- AI는 컴퓨터가 사람과 같은 행동을 할 수 있는 기술을 의미한다.
- ML은 AI를 달성하기 위해 사용되는 방법 중에 하나이다.
- 통계학적 기법을 사용하며 명시적 프로그래밍 없이 데이터로부터 학습을 하여 어떠한 문제를 해결 하는 기술이다.
- Deep learning이란 ML의 기법중에 하나이고 deep neural network기반의 학습법을 의미한다.
- 컴퓨터 vision, 음성 처리, 자연어 처리에서 뛰어난 성능들을 보이면서 ML 기법들 중 가장 활발히 성장하고 있는 기술 분야이다.
- ML의 기초적인 워크 플로우는 다음과 같다.
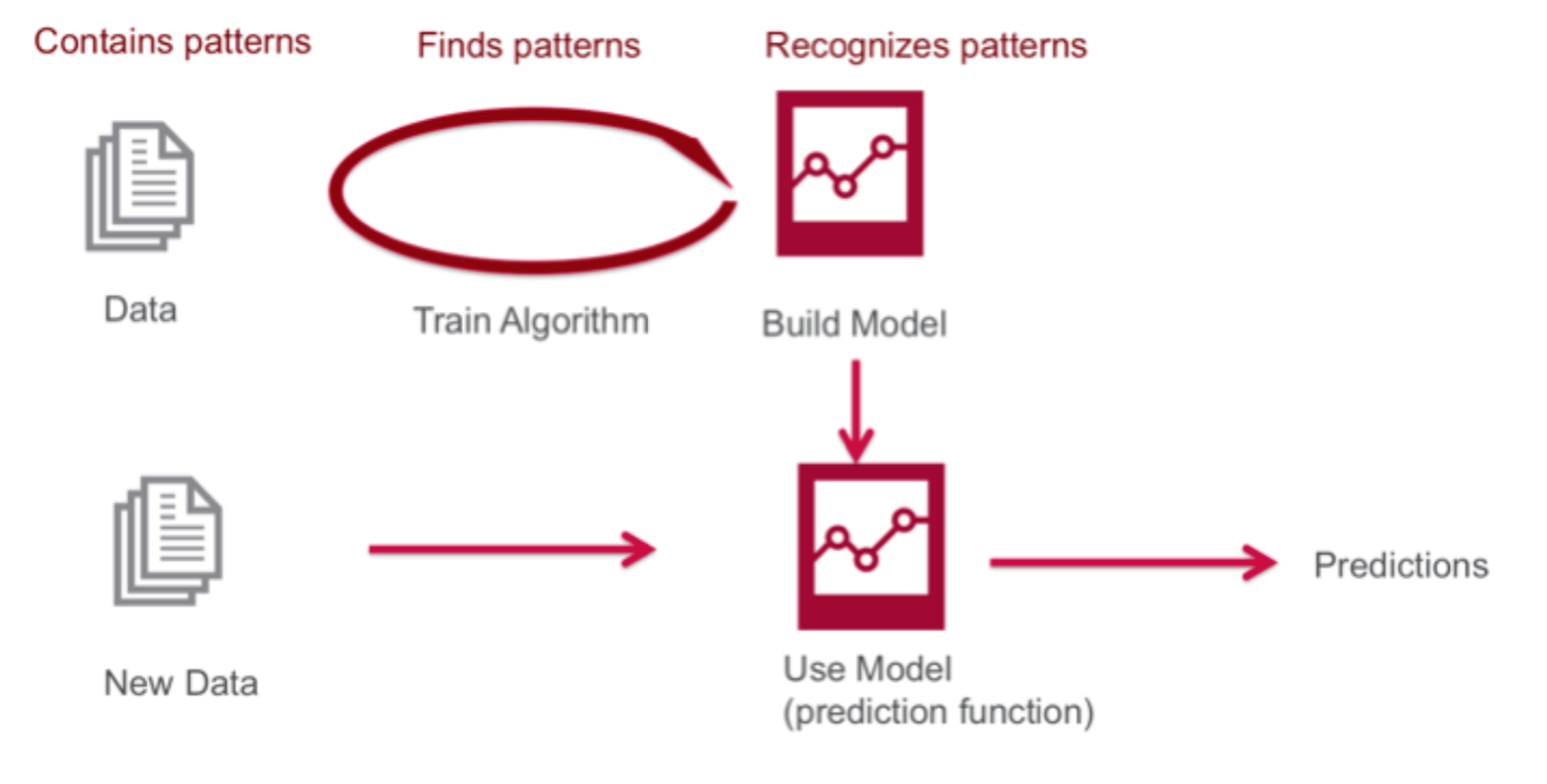
- 그렇기 때문에 평균적으로 training set이 test set보다 훨씬 크다.
- 학습을 시킬 때 test set의 정보가 흘러가게 되면 모델의 정확도에 대한 신뢰도가 줄어든다.
- 학습시키는 data가 좋지 않으면 불안정하고 overfit된 학습 모델이 나오게 된다.
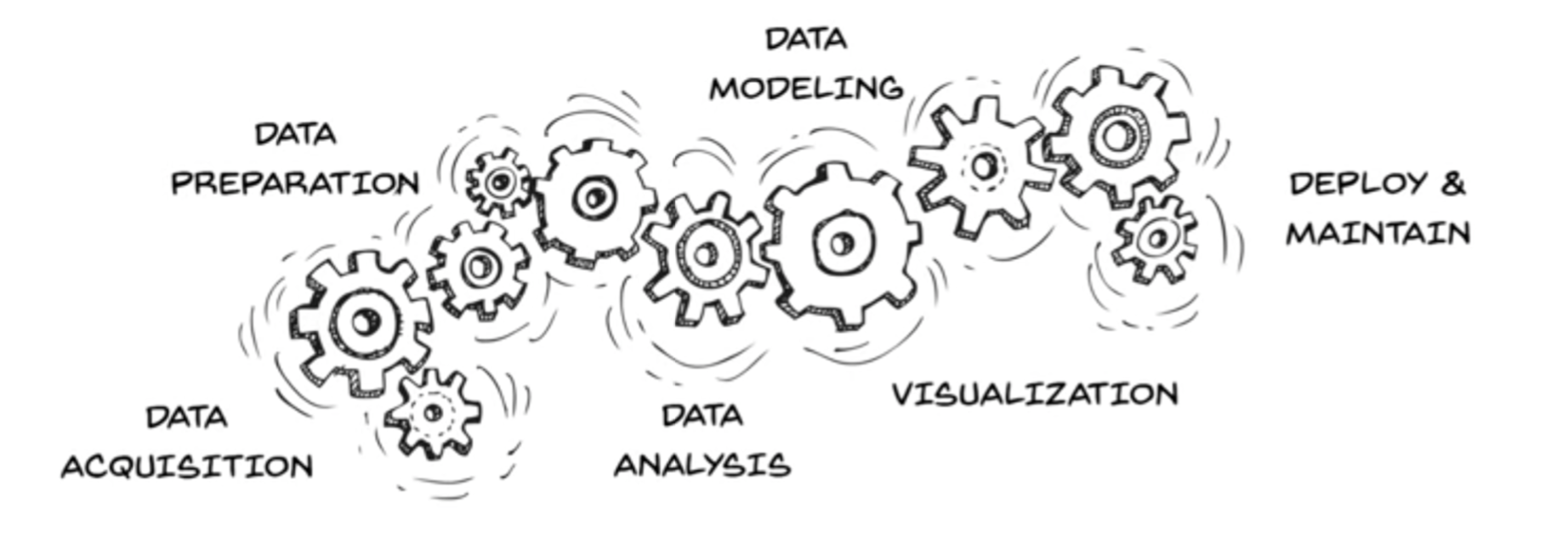
- 단계를 나누자면 데이터를 수집하고 전처리 하는 단계, 전처리 된 데이터로 학습을 하는 단계, 학습된 모델링으로 적용하고 유지보수 하는 단계로 나눌 수 있다.
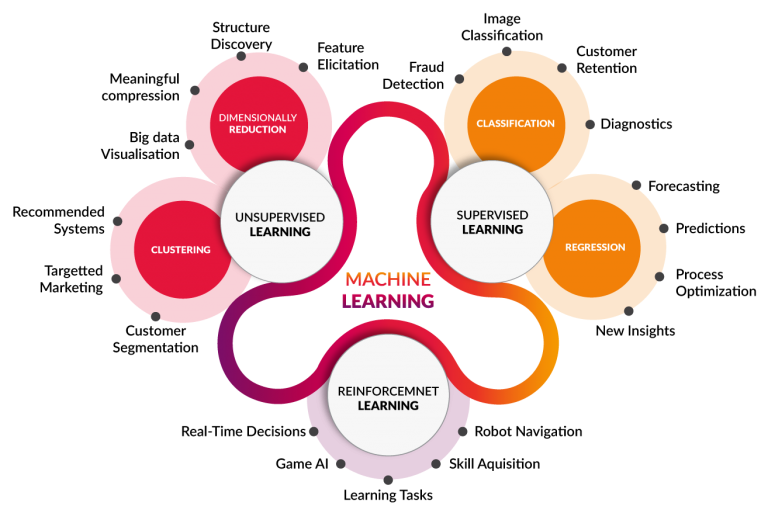
- 머신러닝의 기법들로 분류를 잘 나타낸 그림이다.
- Supervised learning: 문제와 답이 모두 주어진 상태에서 학습을 하는 방법입니다.
- Unsupervised learning: 문제는 있지만 답은 있지 않은 상황에서 학습을 하는 방법입니다.
- Reinforcement(semi-supervised) learning: 보상이라는 개념을 사용하여 부분적으로 정답이 주어진 상황에서 학습을 하는 방법입니다.
Supervised Learning
- Build predictive models based on data with labels(input-output pairs)
- Classification - the outcome is discrete
- Regression - the outcome is real or continuous number
k-Nearest Neighbors
- 이것은 training set이 prediction 단계에 그대로 쓰임으로 lazy learning이라고도 불린다.
- 그만큼 training set이 많을수록 부하가 크다.
- 다음 4가지가 고려된다.
- How to define closeness?
- How to decide k?
- How to make predictions?
- Are all instances considered equally important?
- 다음 코드에서는 위 4가지의 질문에 대한 답을 아래와 같이 두고 간다.
- Euclidean으로 가까운 정도를 정의한다.
- k는 실험적인 값을 사용하되 홀수를 이용하여 타이가 일어나지 않도록 한다.
- majority vote방식을 취한다.
- 여기서는 동일한 weight으로 가정한다.
import numpy as np
import operator
def classify(x_test, dataset, labels, k):
dataset_size = dataset.shape[0]
diff_mat = np.tile(x_test, (dataset_size, 1)) - dataset
sq_diff_mat = diff_mat ** 2
sq_distances = sq_diff_mat.sum(axis=1)
distances = sq_distances ** 0.5
sorted_dist_indicies = distances.argsort()
class_count = {}
for i in range(k):
vote = labels[sorted_dist_indicies[i]]
class_count[vote] = class_count.get(vote, 0) + 1
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
return sorted_class_count[0][0]
def file2matrix(filename):
file = open(filename)
n = len(file.readlines())
return_matrix = np.zeros((n, 3))
class_labels = []
file = open(filename)
index = 0
for line in file.readlines():
line = line.strip()
tokens = line.split('\t')
return_matrix[index, :] = tokens[0:3]
class_labels.append(tokens[-1])
index += 1
return return_matrix, class_labels
'''
데이터는 아래와 같이 들어오게 된다. (연간 마일리지 수, 연간 게임 사용 %, 연간 아이스크림 소비량)
40920 8.326976 0.953952 largeDoses
14488 7.153469 1.673904 smallDoses
26052 1.441871 0.805124 didntLike
75136 13.147394 0.428964 didntLike
38344 1.669788 0.134296 didntLike
72993 10.141740 1.032955 didntLike
...
...
'''
def apply_normalizer(dataset, offset, divisor):
dataset_normalized = np.zeros(dataset.shape)
N = dataset.shape[0]
dataset_normalized = dataset - np.tile(offset, (N,1))
dataset_normalized = dataset_normalized / np.tile(divisor, (N,1))
return dataset_normalized
def normalize_minmax(dataset):
minval = dataset.min(0)
maxval = dataset.max(0)
dataset_normalized = apply_normalizer(dataset, minval, maxval-minval)
return dataset_normalized, minval, maxval-minval
def normalize_meanstd(dataset):
meanval = dataset.mean(0)
stdval = dataset.std(0)
dataset_normalized = apply_normalizer(dataset, meanval, stdval)
return dataset_normalized, meanval, stdval
x, y = file2matrix('datingTestSet.txt')
X_normalized, off, div = normalize_minmax(x)
print(X_normalized)
print("offset:", off, "; divisor:", div)
X_normalized, off, div = normalize_meanstd(x)
print(X_normalized)
print("offset:", off, "; divisor:", div)
X, y = file2matrix('datingTestSet.txt')
holdout_ratio = .2
N = X.shape[0]
N_ts = int(N*holdout_ratio)
N_tr = N - N_ts
X_tr = X[0:N_tr,:]
y_tr = y[0:N_tr]
X_ts = X[N_tr:,:]
y_ts = y[N_tr:]
X_normalized_tr, off, div = normalize_minmax(X_tr)
X_normalized_ts = apply_normalizer(X_ts, off, div)
n_errors = 0
y_pred_ts = []
for i in range(N_ts):
y_pred_ts.append(classify(X_normalized_ts[i], X_normalized_tr, y_tr, 5))
if(y_pred_ts[i] != y_ts[i]):
n_errors += 1
print("the accuracy is: %f" % (1 - n_errors/float(N_ts)))
print("the error rate is: %f" % (n_errors/float(N_ts)))
print("\n---- (Y_true, Y_pred) pairs ----")
print(*list(zip(y_ts, y_pred_ts)), sep="\n")
이미지 출처: http://www.cognub.com/index.php/cognitive-platform/
PREVIOUSOpenssl로 인증서 생성
NEXTStatic Analysis