시스템 디자인 인터뷰 단계
- Clarificiations을 제대로 해야한다. SDI(System Design Interview)는 정해진 답이 없기 때문에 주어진 시간안에 큰 설계를 끝내야 함으로 항상 명확한 범위를 설정해야 합니다. 트위터의 디자인을 설계할때 트윗에 사진과 비디오가 포함되는지, 핫 트렌드 주제를 표시할것인지, 푸시 알림이 있는지, 검색 기능이 있는지 등을 고려해야 합니다.
- 시스템 설계시 규모도 생각해야 합니다. 나중에 확장, 로드 밸런싱 및 캐싱에 집중할 때에도 도움이 됩니다. 트윗의 수, 트윗 보기 수, 초당 타임라인 생성 수과 같은규모를 고려해야 하고 얼마나 많은 스토리지가 필요한지, 네트워크 대역폭 사용량은 어느정도인지 생각해야 합나디.
- 시스템에 예상되는 API를 정의합니다.
- 데이터의 모델을 정의해야 합니다. 어떤 데이터베이스 시스템을 사용할지(NoSQL, SQL을 쓸지)를 정해야 합니다. 읽기/쓰기 요청을 처리하기위해 읽기가 많다면 NoSQL이 유리할 것이고 쓰기 및 업데이트가 많을 경우 SQL이 적합할 것입니다. SQL은 데이터 무결성을 보장해주며 명확한 스키마가 사용자와 데이터에게 중요한 경우 좋고 NoSQL은 정확한 데이터 구조를 알 수 없거나 변경/확장 될 수 있는 경우, 막대한 양의 데이터를 다뤄야 하는 경우 수평으로 확장이 필요한 경우가 적합합니다.
- 이후 세부 디자인적으로 논의를 할 것입니다. 이때 답은 없는 것을 기억하십시오. 서로 시스템 제약을 염두해 두면서 다른 옵션간의 절충안을 고려해야 합니다.
- 병목현상에 대한 것을 논의하고 완화하기 위한 다양한 접근 방식을 논의해야 합니다.
시스템 디자인시 고려해야 할 점
- What are the diffrent architectural pieces that can be used?
- How do these pieces work with each other?
- How can we best utilize these pieces: what are the right tradeoffs?
Distributed Systems
- 다음과 같은 개념들이 핵심 개념입니다.
Scalability
- It is the capability of a system, process, or a network to manage increased demand. 증가하는 수요를 위해 evolve할 수 있는 시스템은 scalable하다고 말할 수 있습니다.
- 증가의 이유는 증가된 트랜젝션과 같은 이유로 확장을 할텐데 이때 성능 손실 없이 확장을 해야 합니다. 일반적으로 확장 가능한 시스템 디자인을 했어도 management or environment cost때문에 그런 시스템 확장에 제약이 있는데 예를들면 컴퓨터가 물리적으로 멀리 떨어져 있어서 네트워워크 속도가 느려질 수 있습니다.
- 일부 작업은 atomic한 특성이나 시스템 디자인의 flaw로 인해 분산처리를 할 수 없을텐데 scalable한 아키텍처는 가능한 이러한 상황을 피하고 참여하는 모든 노드의 부하를 균등하게 분산하려고 시도합니다.
- Horizontal scaling은 더 많은 서버를 붙여서 source를 늘리는 것이고 vertical scaling은 기존 서버에 더 많은 전력(CPU, RAM, storage, etc)를 늘리는 것입니다. 수평확장은 동적으로 확장하는 것이 더 쉬운반면 수직 확장은 단일 서버의 capacity에 제한이 되고 해당 용량을 초과할때에는 종종 가동 중지 시간이 포함됩니다. 수평 확장에 좋은 예는 MongoDB이고 수직 확장에 좋은 예는 MySQL입니다.
Reliability
- Reliability is the probability a system will fail in a given period. 분산 시스템은 소프트웨어 또는 하드웨어 구성 요소 중 하나이상의 장애가 발생하더라도 서비스를 계속 제공하는 경우 안정적으로 간주됩니다. redundancy를 통해 하나의 서버에 장애가 생겼을때 바로 다른 정상적인 서버로 서비스를 재개할 수 있는데 이는 비용이 따릅니다.
Availability
- Availability is the time a system remains operational to perform its required function in a specific period. 이 개념은 relability와 비교가 됩니다. 이것은 사용가능함에 대한 이야기입니다. Reliable하면 available합니다. Available한다고 reliable한 것은 아닙니다. 사용 가능하다는 것이 안정적인 것을 보장하지는 않습니다.
Efficiency
- 분산 시스템의 효율성을 측정하기 위해서는 메시지 크기에 관계 없이 시스템의 노드가 전역적으로 보낸 메시지 수와 데이터 교환시 메시지 크기를 단위로 한 응답 시간과 주어진 시간 단위에 보낸 메시지 수의 처리량으로 측정 할 수 있습니다.
- 분산 시스템의 효율성은 메시지 수로만 분석 할 수 없는데 이는 네트워크단의 여러가지 요소를 무시하고 측정하는 것이기 때문입니다. 따라서 우리는 대략적인 수치로만 이러한 효율성을 고려합니다.
Manageability
- 이것은 시스템을 수리하거나 유지 관리할 수 있는 단순성과 속도입니다. 고장난 시스템을 수정하는 시간이 늘어나면 availability가 줄어듭니다.
Load balancing
- LB는 분산 시스템의 또 다른 중요한 구성 요소입니다. Responsiveness and availability를 높이는데 도움이 됩니다. 리소스의 상태를 추적하고 오류율이 높은 경우 해당 서버의 트래픽 전송을 차단하고 서버 클러스트 전체에 트래픽을 골고루 분산하는 역할을 합니다.
- LB는 다음 3곳에 추가 할 수 있습니다.
- Between client and web server
- 웹 서버와 application server 또는 캐시 서버와 같은 내부 플랫폼 계층 사이
- Between application server와 DB 사이
Benefits
- 사용자는 더 빠르고 uniterrupted service를 경험합니다.
- Service providers는 downtime이 적고 더 높은 throughput을 경험합니다.
- 병목 현상이 발생하기 전에 예측 분석을 미리 할 수 있습니다.
- 시스템 관리자는 각 컴퍼넌트들이 덜 streesed받고 fewer failed하는 것을 경험 할 수 있습니다.
알고리즘
- Least Connection Method - the fewest active connection을 가진 서버로 트래픽을 보냅니다. 이 방식은 서버 간에 unevenly distributed되었고 persistent client가 많은 경우에 효과적입니다. 왜냐하면 연결은 persistant하게 되지만 서버간의 unevenly distributed되었기 때문에 가장 적은 활동을 하는 서버로 트래픽을 보내면 그 다른 서버의 부하를 줄일 수 있기 때문입니다.
- Least Response Time Method - 이 방식은 fewest active connections이면서 the lowest average response time을 지닌 서버에게 트래픽을 보냅니다.
- Least Bandwidth Method - 초당 메가비트로(Mbps)로 측정된 가장 적은 양의 트래픽을 처리하고 있는 서버를 선택합니다.
- Round Robin Method - 서버 목록을 순환하고 각각의 새 요청을 다음 서버로 보냅니다. 목록의 끝에 도달했을 경우에는 처음 순서의 서버로 다시 보냅니다. 서버의 사양이 동일하고 persistant connection이 많지 않을때 가장 유용합니다.
- Weighted Round Robin Method - 처리 용량이 서로 다른 서버를 더 잘 처리하도록 설계되었습니다. 서버에는 각 가중치가 적용되고 가중치가 높은 서버는 낮은 서버보다 먼저 새 연결을 수신하고 더 많은 연결을 받습니다.
- IP Hash - 클라이언트 IP 주소 해시가 계산되어 요청을 서버로 보냅니다.
Redundant Load Balancers
- 로드 밸런서 하나만 있을때 장애가 발생하면 다른 밸런서가 그 역할을 대신할 수 있습니다. 동일한 기능을 하는 밸런서를 연결하여 클러스터를 구성할 수 있습니다.
Caching
- LB는 계속해서 증가하는 서버에서 수평으로 확장할때 도움이 되지만 캐싱은 이미 가지고 있는 리소스를 훨씬 더 잘 사용할 수 있게 도와줍니다.
- 최근 요청한 데이터는 다시 요청될 가능성이 높습니다. 거의 모든 계층에서 가장 최근에 액세스한 항목을 포함하여 불러옵니다. 주로 다운스트림 수준에 부담을 주지 않으면서 빠르게 데이터를 반환하도록 구현되는 프론트 엔드에 가장 가까운 level에 캐시를 설치합니다.
Application server cache
- 캐시를 요청 노드에 직접 배치하면 응답 데이터를 로컬에 저장 할 수 있습니다. 서비스 요청이 있을때마다 노드는 로컬에 캐시된 데이터가 있으면 바로 반환합니다. 없으면 노드가 디스크에서 데이터를 가져오고 캐시는 메모리와 디스크 어디에도 있을 수 있습니다.
- 노드가 확장될때 각 노드가 자체 캐시 호스트가 될 수도 있지만 LB가 노드 전체에 랜덤하게 요청을 분산하는 경우 동일한 request가 다른 노드로 이동하므로 캐시 miss가 발생하게 될 것입니다. 이를 해결하기 위해서는 global caches와 distributed cashes로 해결합니다.
Content Delivery (or Distribution) Network(CDN)
- CDN은 large amounts of static media를 제공하는 사이트에서 사용되는 일종의 캐시입니다.
- CDN은 로컬에서 사용할 수 있는 경우 해당 콘텐츠를 제공하고 사용할 수 없는 경우는 백엔드 서버에 파일을 쿼리하고 로컬로 캐시한 다음 사용자에게 요청에 관한 서비스를 제공합니다.
- 우리가 building하려는 시스템이 자체 CDN을 가질만큼 크지 않을 경우에는 subdomain을 두어서 Nginx와 같은 lightweight HTTP 서버를 두어서 static media를 제공합니다.
Cache Invalidation
- 데이터가 데이터베이스에서 수정이되면 캐시에서 invalidate가 되어야 할 것입니다. 이러한 문제를 해결하는 것을 cache invalidation이라고 합니다.
- 다음과 같은 3가지 main schemes가 있습니다.
- Write-through cache: 데이터가 캐시와 해당 데이터베이스에 동시에 기록됩니다. 데이터 손실 위험을 최소화 할 수 있지만 모든 쓰기 작업이 두번 수행되어야 하므로 쓰기 작업 대기 시간이 길어지는 단점이 있습니다.
- Write-around cache: write-through 방식과 유사하지만 데이터가 캐시를 우회하여 permanent storage에 직접 저장됩니다. 이 방식은 다시 읽지 않을 write operation을 줄여 줄 수 있지만 최근에 쓰여진 데이터가 cache miss를 읽으키고 back-end storage에서 읽어야하기 때문에 느릴것입니다.
- Write-back cache: 이 방식은 일단 캐시에만 데이터를 쓰고 클라이언트에게 즉각적으로 completion을 confirm합니다. 지정된 간격이나 특정 조건하에서 permanent storage에 쓰기 작업이 일어납니다. 쓰기가 많은 어플리케이션에는 low-latency와 high-throughput을 제공하지만 캐시에만 데이터가 있기 때문에 손실 위험이 있습니다.
Cache eviction policies
- 캐시의 용량이 다 찬 후 캐시 제거를 위한 정책은 다음과 같습니다.
- First In First Out(FIFO): 캐시가 이전 빈도 또는 횟수에 관계없이 먼저 액세스한 첫 번째 블록을 evict합니다.
- Last In First Out(LIFO): 빈도 및 횟수 관계없이 가장 최근에 액세스한 최근(마지막)에 access한 블록을 먼저 제거합니다.
- Least Recently Used(LRU): 가장 적게 사용된 항목을 버립니다.
- Most Recently Used(MRU): 가장 최근에 used한 item을 버립니다.
- Least Frequently Used(LFU): item이 사용된 빈도수를 계산하고 가장 적게 사용된 것을 폐기합니다.
- Random Replacement(RR): 무작위로 선택하고 공간을 만들기 위해 아이템을 버립니다.
Data Partitioning
- 큰 DB를 여러개의 작은 부분으로 나누는 기술입니다.
- 애플리케이션의 관리를 용이하게 하기 위해서나 로드 밸런싱을 개선하기 위해 여러 시스템에 걸쳐 DB/table을 분할하는 프로세스 입니다.
- 이 방식은 강력한 서버를 두어 vertically grow하는 것이 아니라 horizontally add하는 것이 더 좋은 방법일때 data partitioning을 쓰는게 좋습니다.
Partitioning Methods
- Horizontal Partitioning: Diffrent row를 다른 테이블에 넣습니다. 예를들어 우편번호의 정보를 넣을때 1-10000에 해당하는 정보들은 하나의 테이블에 넣고 그 이상의 우편번호들은 다른 테이블에 넣습니다. 이러한 특성 때문에 range-based Partitioning 혹은 Data Sharding이라고 불립니다. 이 방식은 range의 기준을 제대로 잡지 못한다면 unbalanced server가 되어버릴 것입니다.
- Vertical Partitioning: 이 방식은 a specific feature로 각자의 서버에 테이블을 저장하는 것입니다. 트위터의 경우 유저 정보, 유저가 올린 사진 자료, 팔로워들에 대한 데이터들을 각각 별개의 테이블로 각자 다른 DB에 저장하게 하는 것입니다. 이 방식은 구현이 직관적이고 어플리케이션에 영향을 덜 미칩니다. 하지만 이 방식의 문제점은 서버가 growth할때 기능별 DB를 추가로 partition해야 할것입니다. 왜냐하면 단일 서버에서 140 million user의 10 billion photos를 처리 할 수 없기 때문입니다.
- Directory-Based Partitioning: 위 두가지의 문제를 어느정도 해결할 수 있는 방식은 lookup service table을 만들어서 우리가 이미 partitionoing한 정보를 알고 DB 액세스 코드를 가져오는 방식으로 partitioning을 하는 것입니다. 따라서 특정 data entity가 어디에 reside하는지 찾기 위해 directory server에 query를 날려서 결과를 얻습니다. 그 서버는 tuple key와 DB 서버간에 맵핑 정보를 지니고 있습니다. 이러한 방식은 애플리케이션에 영향을 주지 않고 DB pool에 서버를 추가하거나 partitioning scheme를 바꿀 수 있게 해줍니다. 하지만 찾는 cost가 조금 더 들것입니다.
Partitioning Criteria
- Criteria는 method와는 다르게 각 테이블을 어떻게 split해서 다른 server에 분배하느냐이다. Method는 좀 더 큰 의미로 어떤 방식으로 partitioning을 할 것인지, organize the table을 할 것인지에 대한 개념이다. Vertical로 나눌때에도 hash-based partitioning기법으로 각 사진 특성에 대해 서로 다른 테이블로 data를 partitioing 할 수 있다.
- Key or Hash-based Partitioning: 저장할 entity의 일부 특성을 가지고 hash function을 적용합니다. 그리고 그 digest를 partition number로 사용합니다. 100개의 DB서버가 있다고 할 때, 새로운 레코드가 삽입될때마다 해시 함수는 ID%100이 될것이며 서버간에 데이터를 균일하게 할당할 것입니다. 하지만 이 방식은 새로운 서버가 추가 되었을때 데이터를 redistribution해야 하며 그 동안 service에 downtime이 생길 것입니다.
- List partitioning: 각 파티션에는 a list of values가 있으므로 우리가 새로운 레코드를 넣으려고 할때 어떤 partition이 키를 contain하고 있는지 확인 한 다음 저장할 것입니다. 예를들어 스웨덴, 필란드, 또는 덴마크에 관한 데이터는 Nordic countries에 관한 partition에 저장될 것입니다.
- Roudn-robin partitioning: 균일한 데이터 배포를 보장하는 간단한 전략입니다. n개의 partition으로 i개의 tuple을 파티션에 할당합니다. (i mod n)
- Composite Partitioing: 위 방식들 중 하나 이상을 혼합하여 새로운 방식을 만듭니다. List partitioning후 hash-based partitioning을 할 수 있을 것입니다. Consistent hashing은 hash로 key-space를 줄이고 list한 composition partitioing의 한 종류로 생각 할 수 있습니다.
Common Problems of Data Partitioning
- 파티셔닝이 된 데이터베이스에는 join과 같은 여러가지 operation에 대한 constraints가 존재합니다. 왜냐하면 더 이상 동일한 서버에서 여러 작업이 실행되지 않기 때문입니다.
- Joins and Denormalization: 한 서버에서는 join을 실행하는 것이 간단하지만 데이터베이스가 분할되고 여러 시스템에 분산되면 join을 실행 할 수 없을 수도 있습니다. 이러한 join을 실행시키려면 여러 서버에서 데이터가 컴파일되어야 해서 성능이 효율적이지 않습니다. 이것을 해결하기 위해서는 DB의 denormalize인데 이러면 data inconsistency와 같은 denormalization’s perils(위험)을 가지게 됩니다. 여기서 denormalization이란 읽는 시간을 최적화 하도록 설계된 데이터베이스이며 join 연산의 비용을 줄일 수 있습니다. 하나 이상의 테이블에 데이터를 중복해 배치합니다. 예를들어 courses와 teachers라는 두 테이블이 있을때 courses 테이블에 teacherID는 들어갈 수 있어도 teacherName은 안 들어갈 것이다. 왜냐하면 teachers 테이블에 이미 그 데이터가 있기에 중복할 필요가 없기 때문이다. 정규화 테이블에서는 course name과 teacher name을 얻기 위해서 두 테이블을 join할 것이다. 하지만 데이터가 많아지면 이러한 join이 힘들어진다. 이때 데이터를 중복하면서까지 비정규화 과정을 거치게 되는 것이다. 하지만 그만큼 중복된 데이터가 많기 때문에 저장공간이 더 필요로 하고 어느 데이터(teacherID, teacherName)이 올바른 것인지 검증하기 어려울 수 있다. 데이터를 고치려면 둘다 고쳐야 하기 때문이다. 데이터 update나 write비용이 더 들게 되고 코드 작성도 보다 어렵다.
- Referential integrity: 파티셔닝이 된 데이터베이스에서는 integrity constraints와 같은 integrity가 지켜지기 어려울 수 있습니다. 서로 다른 데이터베이스 서버에는 그런 constraint를 지원하지 않습니다(지원할 경우 외래키가 함부로 삭제 될 수 없게 함). 때문에 애플리케이션에서 이런 SQL 작업을 실행해야 합니다.
- Rebalancing: 파티셔닝 scheme을 바꿔야 하는 경우는 데이터 distribution이 균일하지 않거나 특정 파티션에 load가 많은 경우가 그렇습니다. 이러한 경우 더 많은 DB 파티션을 creat하거나 기존 파티션을 rebalance해야 합니다. 즉 모든 기존 데이터가 새 위치로 이동하게 됩니다. 이때 downtime없이 이 작업ㅇ르 수행하는 것은 매우 어렵습니다. dicrectory-based partitioning을 하면 시스템의 복잡성이 증가되고 새로운 single point of failure가 생기지만 보다 나은 experience를 줄 수 있습니다.
Indexes
- Indexes는 데이터베이스와 관련해서 잘 알려져 있습니다. 데이터 베이스의 성능이 만족스럽지 않을때 인덱싱을 먼저 확인해야 합니다. 인덱스는 테이블을 더 빠르게 검색하고 원하는 행을 찾게 도와줍니다. 빠른 랜덤 조회와 정렬된 레코드의 효율적인 액세스를 위한 기반을 제공합니다.
- 인덱스는 속도를 드라마틱하게 올릴 수 있지만 추가 키때문에 자체적으로 크기가 커질 수 있습니다.
- Active index가 있는 테이블에 대해 row를 추가하거나 기존 row를 업데이트할 때 인덱스도 같이 업데이트 됩니다. 이것이 write performance를 떨어뜨립니다. 이러한 이유로 테이블에 불필요한 인덱스를 추가하는 것은 피하고 더 이상 사용하지 않는 인덱스는 제거해야 합니다.
- 인덱스를 더하는 것은 search queri의 performance를 향상시키는 것이고 database의 goal은 거의 읽히지 않고 자주 사용되는 데이터를 저장하는 데이터 저장소의 역할을 제공한다고 할 수 있습니다. 이 경우 자주 사용하는 operation의 performance(write)의 performance가 떨어진다는 것은 reading을 위해 performance가 증가하는것 보다 가치가 있지 않습니다.
- 인덱스를 사용하지 않는 칼럼을 조회하는 경우 full scan을 할 것입니다. Indx가 적용된 컬럼에 insert, update, delete가 수행된다면 인덱스를 추가하거나, 기존 인덱스를 사용하지 않고 업데이트된 데이터에 인덱스를 추가하거나, 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업들을 해야해서 오버헤드가 생깁니다.
Proxies
- 프록시 서버는 클라이언트와 백엔드 서버 사이의 중간 서버입니다. 다른 서버의 리소스를 찾는 클라이언트의 요청에 대한 중개 역할을 하며 모든 프록시 서버는 캐싱이 가능합니다.
- 하드웨어, 또는 소프트웨어 형태로 있을 수 있습니다.
- 프록시는 요청을 필터링 하거나 헤더를 추가하거나 지우는 등의 작업, 암호화 작업등 transform request를 하고 많은 request에 관해 cache합니다.
- Proxy(대리) Server는 클라이언트가 서버의 정보를 요구할때 대신 서버에 요청을 보내기때문에 클라이언트의 ip를 숨기고 proxy 서버의 ip를 통해 대화하게 됩니다. 따라서 개인정보를 보호 할 수 있습니다.
- 다음은 프록시 서버의 types에 관한 설명이다.
Open Proxy
- 모든 인터넷 사용자가 액세스 할 수 있는 프록시 서버입니다. 일반적으로 프록시 서버는 closed proxy로 특정 그룹의 사용자만을 위해 DNS or web pages와 같은 인터넷 서비스를 포워드 합니다. 다음과 같은 2가지 유형이 있습니다.
- Anonymous Proxy: 서버로써 정보를 드러내지만 initial IP address는 숨깁니다. 그 정보가 밝혀질 수는 있을지라도 클라이언트가 IP를 숨기고자 하려고 할 때 사용 될 수 있습니다.
- Transparent Proxy: 서버와 first IP address 모두를 볼 수 있는 HTTP headers를 지원합니다. 주로 웺사이트를 캐시하는데 사용 됩니다. 회사의 경우 프록시 서버를 통해 SNS 접속을 차단 할 수도 있고 조직의 트래픽을 모니터링 하는데 사용 될 수도 있습니다. 또한 캐싱을 통해 100대의 업데이트가 아닌 프록시 서버 1대의 업데이트로 대역폭을 줄여 줄 수 있습니다.
Reverse Proxy
- 클라이언트가 특정 웹사이트 혹은 서버에 리퀘스트를 날릴때 서버에 직접 가지 않고 리버스 프록시가 대신 회사 내의 서버에 요청을 한 후 그 resource를 받아 다시 client에게 전달하게 도와주는 것입니다. 이렇게 하면 client는 마치 reverse proxy가 서버인 것으로 알게되고 회사 내의 네트워크 자체를 숨길 수 있습니다. 보안이 더 강해지며 우리가 WEB(Apache, nginx)를 DMZ에 두고 WAS(Tomcat)을 분리하여 내부망에 분리하는 형태를 reverse proxy라고 볼 수 있다. 이때, WEB이 reverse proxy이다.
Redundancy and Replication
- Redundancy는 일반적으로 백업 또는 fail-safe 형태로 시스템의 reliability를 높이기 위해 시스템의 중요한 구성 요소 또는 기능을 복제하는 것입니다.
- Single points of failure을 제거하는데 중요한 역할을 하며 필요한 경우 백업을 제공합니다. 서비스 인스턴트가 두개 있고 하나가 실패했을시 시스템은 다른 인스턴스로 장애 조치를 할 수 있습니다.
- Replication은 reliability, fault-tolerance, or accessibility를 높이기 위해 중복된 리소스들간에 일관성을 유지하기 위해 정보공유를 하는 것을 의미합니다. 이때 리소스들이란 소프트웨어나 하드웨어 컴퍼넌트를 의미합니다.
- 주로 DBMS에 사용되며 오리진과 카피사이의 primary-replica관계로 사용합니다. The primary 서버는 모든 업데이트를 받아들이고 이후 복제 서버로 ripple합니다. 각 replica들은 모든 업데이트가 성공적으로 수신 받은 후에 이후 업데이트를 보낼 수 있도록 허용합니다.
SQL vs NoSQL
- 데이터베이스 기술과 관련해서는 만능 솔루션(one-size-fits-all solution)은 없습니다. 각각의 상황에 따라 달려있습니다.
SQL
- 관계형 데이터베이스는 행과 열로 되어 있다. 각 row는 information을 담고 있고 각 column은 각 데이터의 속성을 담고 있다.
NoSQL
- 대표적인 4가지 타입이 있습니다.
- Key-Value Stores: 데이터가 key-value pairs로 저장이 됩니다. Redis, Voldemort, Dynamo와 같은 것이 있습니다.
- Document Databases: 데이터들이 다큐먼트 안에 저장이 되어 있고 다큐먼트는 콜렉션으로 그룹지어져 있습니다. 각각의 다큐먼트들은 서로 다른 구조를 지닐 수 있습니다. CouchDB, MongoDB가 대표적인 유형입니다.
- Wide-Column Databases: 테이블 대신 columnar 데이터베이스에 column families가 있다. 관계형 데이터베이스와는 다르게 우리가 모든 columns에 관한 것을 알 필요가 없고 같은 수의 columns들이 각 row마다 같지도 않다. 이것은 large datasets을 분석하는데 적합하고 Cassandra, HBase가 있다.
- Graph Database: 이 데이터 베이스는 관계가 가장 잘 표현되는 데이터를 저장하는데 사용된다. 데이터는 그래프의 구조 형태인 노드(entities), 속성(information about the entities), 관계(connection between the entities)의 형태로 저장된다. Neo4J, InfiniteGraph가 대표적인 데이터베이스이다.
SQL과 NoSQL의 차이점
- Storage: SQL은 테이블안에 저장되는 형태이지만 NoSQL은 각각 다른 형태의 모델들로써 저장되고 위에 말한 4가지의 다른 타입의 데이터베이스가 있다.
- Schema: SQL은 고정된 형태의 schema를 가지고 있어서 데이터를 넣기 전에 이미 columns에 관한 것이 정의되어야 하고 만약 수정했을 시에는 DB가 offline으로 되어 다시 적용해야하는데 NoSQL의 경우에는 dynmic하게 바꿀 수 있고 각 column에 대한 데이터가 들어가지 않아도 되며 순간순간 새롭게 columns을 추가할 수도 있다.
- Querying: SQL은 SQL 쿼리를 사용하여 매우 강력하게 데이터를 조작할 수 있는 반면에 NoSQL은 데이터를 모으는데 쿼리가 집중되어 있고 UnQL(Unstrucutred Query Language라고 부릅니다. 각각의 데이터베이스마다 서로 다른 문법의 UnQL를 가지고 있습니다.
- Scalability: 대다수의 경우 SQL DB가 vertically(CPU, memory 증가 등) scalable합니다. 여러 서버에 걸쳐 확장은 가능하지만 어려우면서 시간도 많이 소요됩니다. 이에 반해 NoSQL은 horizontally scalable하고 그 과정또한 쉬운 편이다. Vertical scaling에 비해 cost-effective하고 많은 NoSQL들은 데이터를 여러 서버에 자동적으로 distribute한다.
- Relability or ACID Compliancy(Atomicity, Consistency, Isolation, Durability): SQL은 ACID를 만족시키면서 작동합니다. 따라서 데이터의 reliability와 transaction을 실행함에 있어서 safe가 중요하다 여전히 SQL이 나은 선택입니다. 이에 반해 NoSQL은 ACID를 희생하면서 퍼포먼스와 scalability를 높이는데 초점이 맞춰져 있습니다.
Reasons to use SQL DB
- ACID가 보장되어야 할때. 전자 상거래 및 금융 애플리케이션 경우 ACID 준수가 선호되어 SQL을 사용하는 편입니다.
- 데이터 자체가 strucutred되어 있고 unchanging할때. 더불어 비즈니스 자체가 massive growth하지 않고 일관성을 유지할때.
Reasons to use NoSQL DB
- 대다수의 빅데이터는 관계형 데이터베이스와 다르게 데이터를 처리해서 NoSQL이 크게 성공적이다. 구조가 거의 없는 대용량 데이터를 저장할때 사용 하면 된다.
- 클라우드 컴퓨팅 및 스토리지를 최대한 활용해야 할 때. 클라우드 스토리지는 비용절감면에서는 탁월한 선택이지만 스케일 업을 할 때에는 여러 서버에 데이털르 분산해야한다. 이 때 Cassandra와 같은 NoSQL데이터 베이스가 쉽게 확장 할 수 있도록 도와준다.
- Rapid development 환경. 빠른 개발과 데이터 구조를 자주 업데이트 해야 하는 시스템에서 NoSQL은 탁월하다.
CAP Theorem
Background
- 분산 시스템에서는 다양한 오류가 발생할 수 있는데 예를 들어 서버가 충돌하거나, 영구적 오류가 발생하거나, 디스크 손상 혹은 데이터 손실이 발생하거나 네트워크 연결이 끊어져서 일부 시스템에 액세스 할 수 없게 되는 경우들이 있습니다. 분산 시스템이 다양한 리소스를 최대한 활용하기 위해서는 어떻게 자체 모델을 구현할 수 있을까? 라는 질문에서 시작되었습니다.
Solution
- CAP theroem은 분산 시스템이 다음 3가지 속성을 모두 동시에 제공하는 것은 불가능하다고 말합니다.
- Consistency(C): 모든 노드가 모든 데이터를 동시에 봅니다. 이것은 유저가 시스템의 모든 노드에서 read or write를 할 수 있고 동일한 데이터를 받을 수 있음을 의미합니다. 이것은 최신 버전의 데이터를 카피하는 것과 동일한 의미입니다.
- Availability(A): A non-failing node에 의해서 수신한 모든 요청이 응답을 받는 것을 의미합니다. 심각한 네트워크 장애가 발생하더라도 모든 request는 반드시 terminate되어야 합니다. 간단한 말로, 시스템의 하나 이상의 노드가 다운되더라도 시스템에 액세스 할 수 있는 능력을 의미합니다.
- Partition tolerance(P): 파티션은 시스템의 두 노드 간의 communication break(or a network failure)를 의미합니다. 즉, 두 노드가 모두 작동은 하지만 서로 통신을 할 수 없습니다. A partition-tolerant 시스템은 시스템에 파티션이 있어도 계속 작동합니다. 이러한 시스템은 전체 네트워크의 장애를 초래하지 않는 모든 네트워크 장애를 견딜 수 있습니다. 데이터는 노드와 네트워크의 조합에 걸쳐 충분히 복제되어 간헐적인 중단이 발생해도 시스템을 계속 돌릴 수 있습니다.
- CAP theorem에 따르면 모든 분산 시스템은 세가지 속성 중 두가지를 선택해야 합니다. 그러나 not partition-tolerant system은 C나 A중에 무조건 포기해야 되는 시스템임으로 CA는 고려할 수 있는 옵션이 아닐 것입니다. 따라서 네트워크 파티션이 존재할 수 밖에 없는 시스템에서는 Consistency나 Availability 중에서 선택을 해야만 합니다.
- Consistent를 유지하고 싶을때 모든 노드는 다른한 순서로 동일한 업데이트를 확인해야 합니다. 하지만 네트워크가 파티션을 잃어버렸을 때에는 다른 노드에게 업데이를 할 수 없게 되고 최신 정보를 가질 수 없게 됩니다. 이때 할 수 있는 것은 파티션 request serving을 중단해야하는데 이러면 서비스가 100% available하지 않게 됩니다. 따라서 파티션이 생길때에는(P가 충족되지 못할때) CA가 존재 할 수 없고 분산시스템에서 가능한 경우는 CP, AP중 하나를 선택해야 하는 것입니다.
PACELC Theorem
Background
- CPA theorem에 의하면 결국 분산시스템은 파티션을 피할 수 없으므로 Consistency or availability를 선택해야만 합니다. ACID를 만족하는 관계형 데이터베이스에서는 consistency를 선택했지만(상대 피어에서 확인 할 수 없을시 응답 거부의 방법으로 일관성 유지) NoSQL 기반의 BASE(Basically Available, Soft-state, Eventually consistent) DB의 경우들은최신 데이터인지 확인하지 않고 로컬 데이터를 응답함으로써 availability를 선택했습니다. 만약 네트워크에 파티션이 없다면 무슨 선택 할 수 있을지?라는 CPA에서 말하지 않는 부분에 대해 설명하기 위해 탄생했습니다.
Solution
- 파티션이 있는 경우 C와 A 사이에서 절충할 수 있습니다.
- 파티션이 없는 경우 시스템은 L과 C사이에서 tradeoff 관계가 형성됩니다.
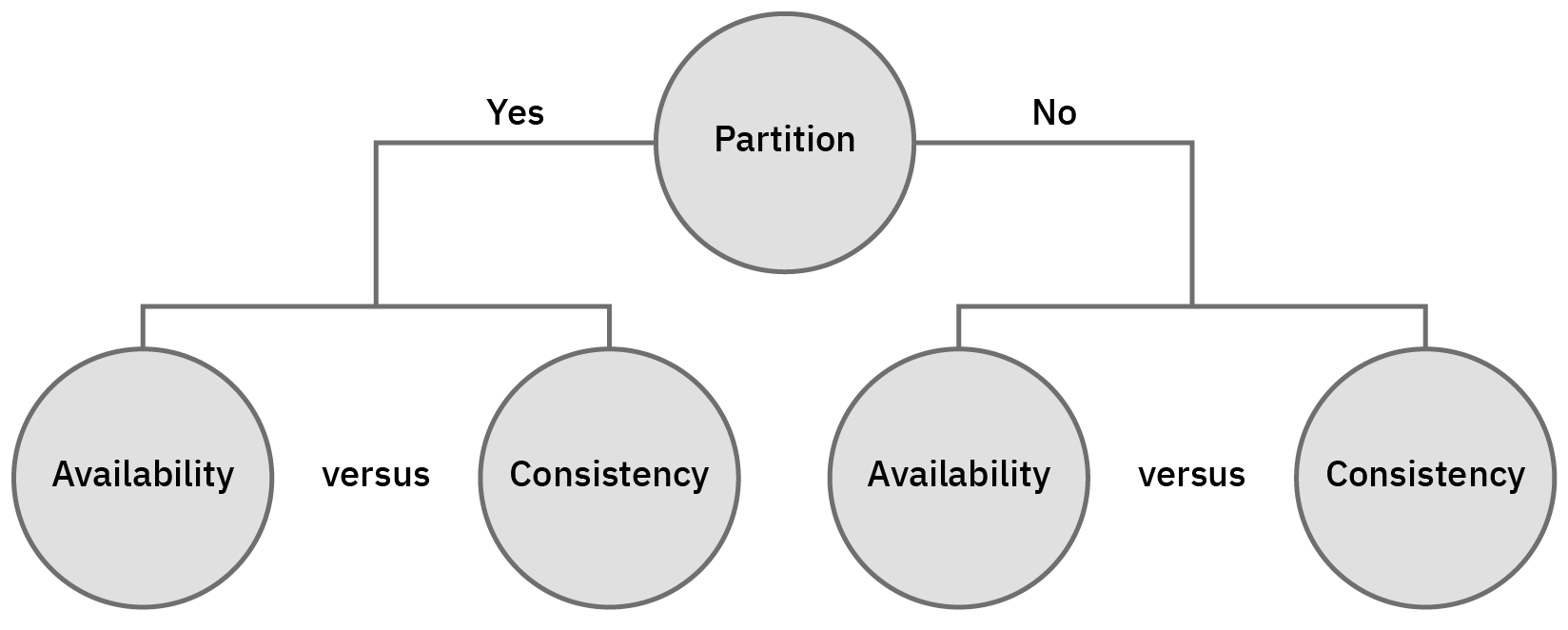
- PAC는 CAP theorem과 동일하며 ELC가 추가된 것입니다. 여기에서는 우리가 high availability를 복제를 통해 유지한다는 가정이 있습니다. 그래서 만약 failure가 일어났을때 CAP theorem이 우세합니다. 하지만 그렇지 않을 경우에는 우리는 여전히 consistency와 latency 사이의 tradeoff를 고려할 수 있습니다.
Example
- Dynamo와 Cassandra는 PA/EL 시스템입니다. 파티션이 발생할 때 Availability를 선택하고 파티션이 없을때에는 Latency를 선택합니다.
- BigTable과 HBase는 PC/EC 시스템 입니다. 항상 Consistency를 선택합니다.
- MongoDB는 PA/EC로 간주 될 수 있습니다. primary와 secondaries가 있는데 모든 읽기 쓰기는 primary에서 일어나고 비동기식으로 레플리카가 일어납니다. 만약 파티션이 생기는 경우에는 secondaries로 복제가 되지 않는 경우가 생겨 데이터가 손실 될 수 있습니다. 따라서 파티션 동안에는 consistency가 잃는다고 볼 수 있습니다.
PREVIOUSPrivacy engineering
NEXTTiny URL case