





Introduction to AI
What is AI?
Artificial Intelligence (AI) refers to technology that enables computers to perform tasks that would normally require human intelligence—reasoning, learning, problem-solving, understanding language, and recognizing patterns.
AI is not a single technology. It is an umbrella term covering a spectrum of approaches:
- Narrow AI (Weak AI): Systems designed to perform a specific task (e.g., spam filtering, image recognition, recommendation engines). All production AI systems today fall into this category.
- General AI (AGI): A hypothetical system with human-level reasoning across any domain. Does not yet exist.
- Superintelligence: A hypothetical system that surpasses human intelligence in all dimensions. Speculative.
The hierarchy of the field looks like this:
1
2
3
4
Artificial Intelligence
└── Machine Learning
└── Deep Learning
└── Foundation Models / LLMs
Each layer is a subset of the one above it. Machine Learning is a method to achieve AI. Deep Learning is a subset of ML that uses multi-layer neural networks. Foundation Models (GPT, Claude, Gemini) are large deep learning models trained on massive datasets that can generalize across many tasks.
Why AI Now?
Three conditions converged to make modern AI possible:
- Data: The internet and digitization produced massive labeled and unlabeled datasets.
- Compute: GPU hardware made training large neural networks practical.
- Algorithms: Backpropagation, attention mechanisms, and transformer architectures enabled training at unprecedented scale.
Removing any one of these three would have stalled the current AI era.
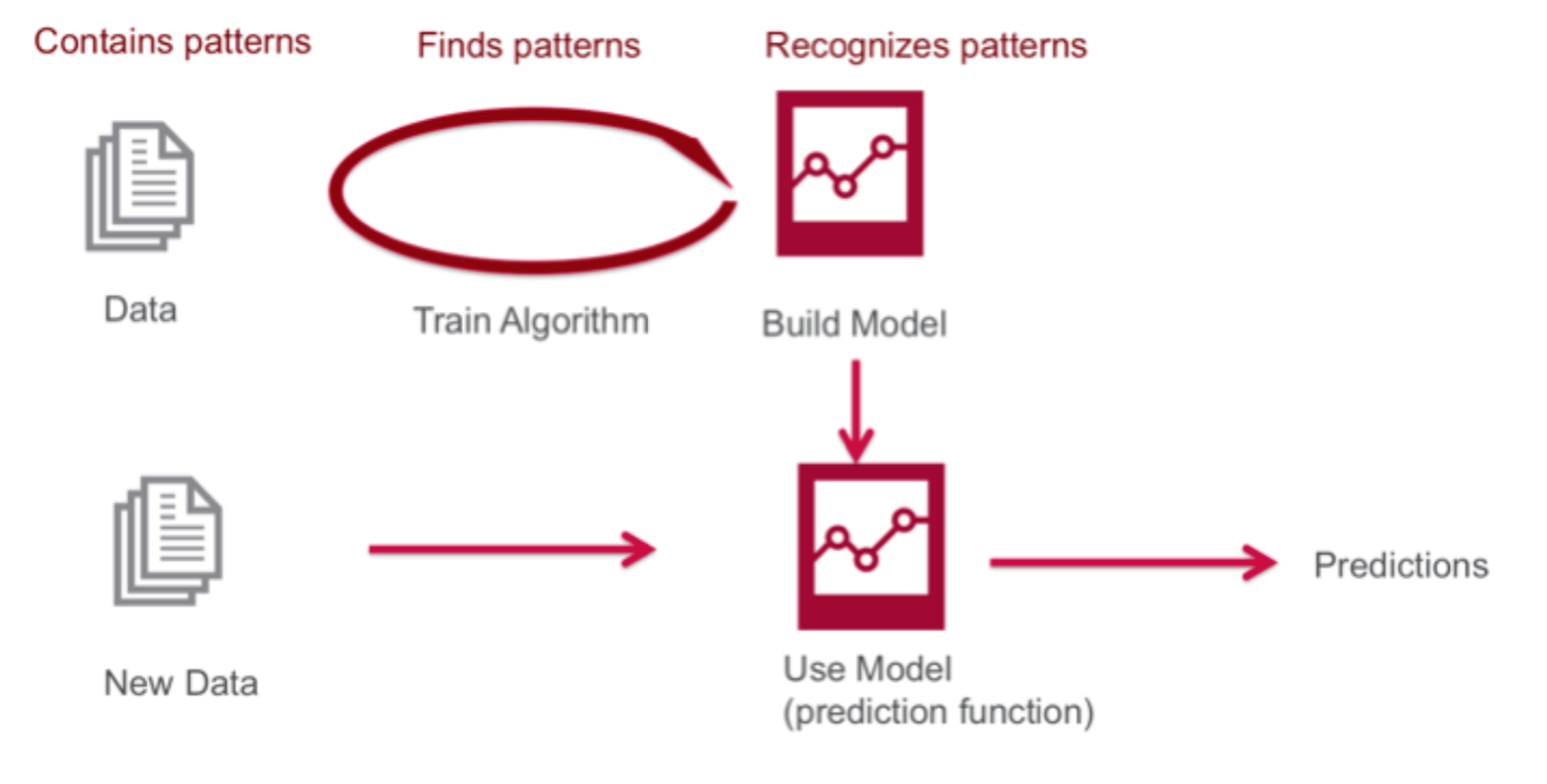
Machine Learning: The Core Approach
Machine Learning (ML) is the practice of building systems that learn from data rather than following explicitly programmed rules.
Traditional programming:
1
Rules + Data → Output
Machine Learning:
1
Data + Output (labels) → Rules (model)
In ML, you show the system many examples and it extracts the underlying patterns. The resulting “rules” (the model) can then generalize to unseen data.
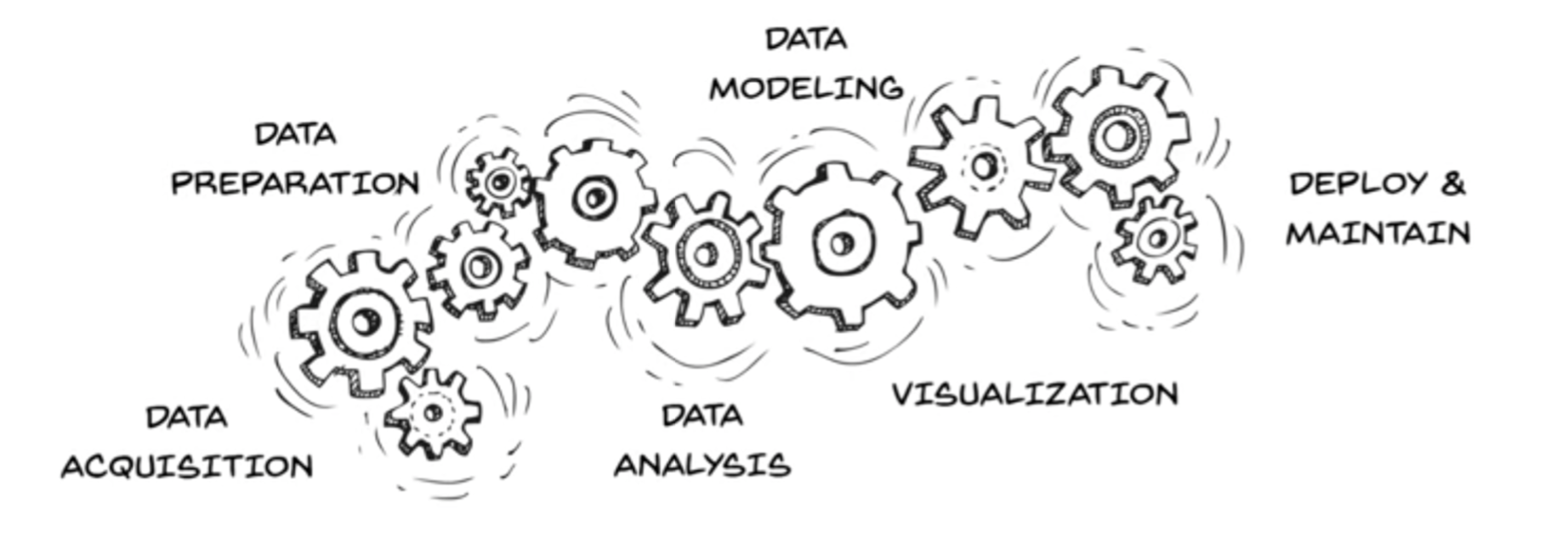
The ML Workflow
A standard ML project follows this lifecycle:
1
2
3
4
5
6
7
8
9
10
11
1. Problem Definition
↓
2. Data Collection & Preprocessing
↓
3. Feature Engineering
↓
4. Model Selection & Training
↓
5. Evaluation
↓
6. Deployment & Monitoring
Key principles:
- The training set should be significantly larger than the test set.
- Data leakage: If test set information leaks into training, model accuracy metrics become unreliable. Always split data before any preprocessing.
- Garbage in, garbage out: Low-quality training data produces unstable, overfitted models regardless of algorithm sophistication.
Training Methodologies
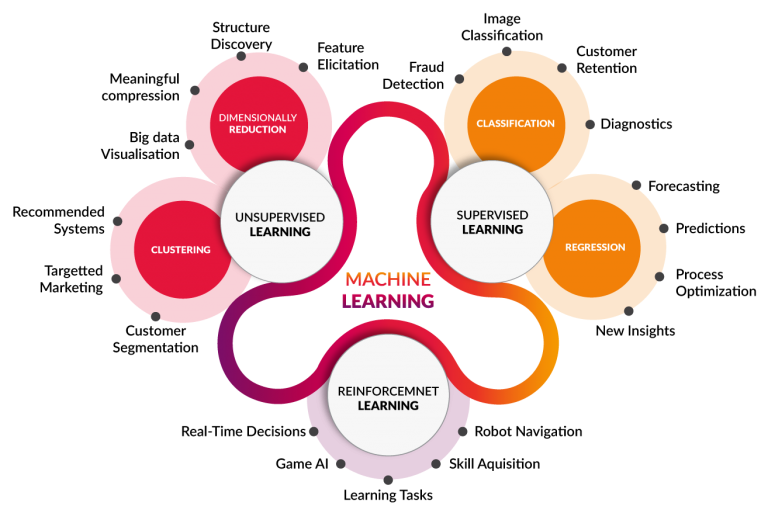
Supervised Learning
Used when the target output ($y$) is known for each training example. The model learns a mapping from inputs ($X$) to outputs ($y$).
\[f: X \rightarrow y\]Two main task types:
| Task | Output Type | Examples |
|---|---|---|
| Regression | Continuous number | House price prediction, temperature forecasting |
| Classification | Discrete category | Spam detection, malware classification, image labeling |
Common algorithms: Linear Regression, Logistic Regression, Decision Trees, Random Forest, SVM, Neural Networks.
In practice, Supervised Learning is the most widely used ML paradigm because labeled data—though expensive to produce—yields the most predictable, evaluable models.
Unsupervised Learning
Used when the target output ($y$) is unknown. The model discovers hidden structure in unlabeled data.
Common tasks:
- Clustering: Group similar data points (e.g., customer segmentation, anomaly detection in network traffic).
- Dimensionality Reduction: Compress high-dimensional data while preserving structure (PCA, t-SNE, autoencoders).
- Generative Modeling: Learn the data distribution to generate new samples (GANs, VAEs).
In security contexts, unsupervised learning is particularly valuable for anomaly detection, where you can’t enumerate all attack patterns in advance.
Reinforcement Learning
The agent learns by interacting with an environment and receiving rewards or penalties. No labeled dataset is required—the signal comes from outcomes.
\[\text{Agent} \xrightarrow{\text{action}} \text{Environment} \xrightarrow{\text{reward + state}} \text{Agent}\]Applications: game-playing AI (AlphaGo), robotics, adaptive security response systems, LLM alignment (RLHF—Reinforcement Learning from Human Feedback).
Deep Learning
Deep Learning uses multi-layer neural networks (deep = many layers) to learn hierarchical representations of data. Each layer learns increasingly abstract features.
1
2
Input Layer → Hidden Layer 1 → Hidden Layer 2 → ... → Output Layer
(raw pixels) (edges, textures) (shapes, parts) (class label)
Deep Learning dominates:
- Computer Vision: CNNs for image classification, object detection
- Natural Language Processing: Transformers for translation, summarization, generation
- Speech Recognition: RNNs and transformers for audio processing
The Transformer Architecture
The transformer (introduced in “Attention Is All You Need”, 2017) is the foundation of modern LLMs. Its self-attention mechanism allows the model to weigh the relevance of every token relative to every other token in a sequence—enabling far better long-range understanding than prior RNN-based models.
All major foundation models (GPT-4, Claude, Gemini) are transformer-based.
Key Tools and Frameworks
| Tool | Purpose | Use When |
|---|---|---|
| scikit-learn | Classical ML algorithms | Tabular data, explainable models, baselines |
| PyTorch | Deep learning research & production | Custom architectures, research, flexibility |
| TensorFlow / Keras | Deep learning (Google ecosystem) | Production deployment, mobile/edge inference |
| Hugging Face | Pre-trained model hub | Fine-tuning or using existing foundation models |
| XGBoost / LightGBM | Gradient boosting | Structured/tabular data competitions and production |
scikit-learn is the best starting point for classical ML. For deep learning, PyTorch has become dominant in research; Keras (now integrated into TensorFlow) provides a cleaner API for those new to deep learning.
Before You Build: The Data Strategy
The most common mistake in AI projects is jumping to model selection before addressing data. No algorithm compensates for poor data.
A proper AI data strategy must address:
- Data sources: Where does the data come from? Is it representative of the real-world distribution you care about?
- Labeling: For supervised learning, how are labels obtained? Human annotation? Programmatic labeling? Self-supervised methods?
- Class balance: Are classes imbalanced? (e.g., 99% benign traffic, 1% malicious) Imbalanced data requires special handling.
- Data freshness: Does the distribution shift over time? (e.g., new malware families) How will you detect and handle drift?
- Privacy and compliance: Does the data contain PII? What retention and access controls apply?
In security applications especially, class imbalance and concept drift (attackers evolve their techniques) are persistent challenges that affect every model in production.
AI란 무엇인가?
인공지능(Artificial Intelligence, AI)은 추론, 학습, 문제 해결, 언어 이해, 패턴 인식 등 일반적으로 인간의 지능이 필요한 작업을 컴퓨터가 수행할 수 있도록 하는 기술입니다.
AI는 단일 기술이 아닙니다. 다양한 접근법을 포괄하는 상위 개념입니다:
- 좁은 AI (Narrow AI / Weak AI): 특정 작업을 수행하도록 설계된 시스템 (예: 스팸 필터링, 이미지 인식, 추천 엔진). 현재 존재하는 모든 실용적 AI 시스템이 여기에 해당합니다.
- 범용 AI (AGI, Artificial General Intelligence): 어떤 영역에서도 인간 수준의 추론이 가능한 가상의 시스템. 아직 존재하지 않습니다.
- 초인공지능 (Superintelligence): 모든 면에서 인간 지능을 능가하는 가상의 시스템. 현재로서는 이론적 개념입니다.
이 분야의 계층 구조는 다음과 같습니다:
1
2
3
4
인공지능 (Artificial Intelligence)
└── 머신러닝 (Machine Learning)
└── 딥러닝 (Deep Learning)
└── 파운데이션 모델 / LLM
각 레이어는 위 레이어의 부분 집합입니다. 머신러닝은 AI를 달성하기 위한 방법론이고, 딥러닝은 다층 신경망을 사용하는 ML의 부분 집합이며, 파운데이션 모델(GPT, Claude, Gemini)은 대규모 데이터셋으로 훈련된 거대 딥러닝 모델로 다양한 태스크에 일반화가 가능합니다.
왜 지금 AI인가?
현대 AI를 가능하게 만든 세 가지 조건이 동시에 충족되었습니다:
- 데이터: 인터넷과 디지털화가 방대한 레이블 및 비레이블 데이터셋을 만들어냈습니다.
- 연산력: GPU 하드웨어가 대형 신경망 훈련을 실용적으로 만들었습니다.
- 알고리즘: 역전파(Backpropagation), 어텐션 메커니즘, 트랜스포머 아키텍처가 전례 없는 규모의 학습을 가능하게 했습니다.
이 세 가지 중 하나라도 없었다면 현재의 AI 시대는 오지 않았을 것입니다.
머신러닝: 핵심 접근법
머신러닝(ML)은 명시적으로 프로그래밍된 규칙을 따르는 대신 데이터로부터 학습하는 시스템을 구축하는 방법론입니다.
전통적 프로그래밍:
1
규칙 + 데이터 → 출력
머신러닝:
1
데이터 + 출력(레이블) → 규칙(모델)
ML에서는 시스템에 많은 예시를 보여주면 내재된 패턴을 추출합니다. 생성된 “규칙”(모델)은 이후 새로운 데이터에도 일반화하여 적용될 수 있습니다.
ML 워크플로우
표준 ML 프로젝트는 다음의 라이프사이클을 따릅니다:
1
2
3
4
5
6
7
8
9
10
11
1. 문제 정의
↓
2. 데이터 수집 및 전처리
↓
3. 피처 엔지니어링
↓
4. 모델 선택 및 학습
↓
5. 평가
↓
6. 배포 및 모니터링
핵심 원칙:
- Training set은 Test set보다 훨씬 커야 합니다.
- 데이터 누수(Data Leakage): 학습 시 Test set 정보가 유출되면 모델의 정확도 지표가 신뢰할 수 없게 됩니다. 항상 전처리 전에 데이터를 분리해야 합니다.
- 쓰레기 입력, 쓰레기 출력(Garbage in, garbage out): 낮은 품질의 훈련 데이터는 알고리즘 수준에 관계없이 불안정하고 과적합된 모델을 만들어냅니다.
학습 방법론 (Training Methodologies)
지도 학습 (Supervised Learning)
각 훈련 예시에 대해 목표 출력($y$)이 알려져 있을 때 사용합니다. 모델은 입력($X$)에서 출력($y$)으로의 매핑을 학습합니다.
\[f: X \rightarrow y\]두 가지 주요 태스크 유형:
| 태스크 | 출력 유형 | 예시 |
|---|---|---|
| 회귀 (Regression) | 연속적인 수치 | 주택 가격 예측, 기온 예측 |
| 분류 (Classification) | 이산적인 카테고리 | 스팸 탐지, 악성코드 분류, 이미지 레이블링 |
대표 알고리즘: 선형 회귀, 로지스틱 회귀, 의사결정 트리, 랜덤 포레스트, SVM, 신경망.
실무에서 지도 학습이 가장 널리 사용됩니다. 레이블 데이터를 생성하는 비용이 높지만 가장 예측 가능하고 평가하기 쉬운 모델을 만들기 때문입니다.
비지도 학습 (Unsupervised Learning)
목표 출력($y$)이 알려지지 않은 경우 사용합니다. 모델이 레이블 없는 데이터에서 숨겨진 구조를 발견합니다.
주요 태스크:
- 클러스터링: 유사한 데이터 포인트 그룹화 (예: 고객 세분화, 네트워크 트래픽 이상 탐지)
- 차원 축소: 구조를 유지하면서 고차원 데이터를 압축 (PCA, t-SNE, 오토인코더)
- 생성 모델링: 데이터 분포를 학습하여 새로운 샘플 생성 (GAN, VAE)
보안 분야에서 비지도 학습은 특히 이상 탐지에 유용합니다. 가능한 모든 공격 패턴을 사전에 열거할 수 없기 때문입니다.
강화 학습 (Reinforcement Learning)
에이전트가 환경과 상호작용하며 보상이나 패널티를 받아 학습합니다. 레이블 데이터셋이 필요 없고, 신호는 결과로부터 옵니다.
\[\text{에이전트} \xrightarrow{\text{행동}} \text{환경} \xrightarrow{\text{보상 + 상태}} \text{에이전트}\]적용 분야: 게임 플레이 AI (AlphaGo), 로보틱스, 적응형 보안 대응 시스템, LLM 정렬(RLHF—인간 피드백 기반 강화 학습).
딥러닝 (Deep Learning)
딥러닝은 다층 신경망(deep = 많은 레이어)을 사용하여 데이터의 계층적 표현을 학습합니다. 각 레이어는 점점 더 추상적인 특징을 학습합니다.
1
2
입력 레이어 → 은닉 레이어 1 → 은닉 레이어 2 → ... → 출력 레이어
(원시 픽셀) (엣지, 텍스처) (형태, 부분) (클래스 레이블)
딥러닝이 지배적인 분야:
- 컴퓨터 비전: 이미지 분류, 객체 탐지를 위한 CNN
- 자연어 처리: 번역, 요약, 생성을 위한 트랜스포머
- 음성 인식: 오디오 처리를 위한 RNN과 트랜스포머
트랜스포머 아키텍처
트랜스포머(“Attention Is All You Need”, 2017 논문)는 현대 LLM의 기반입니다. 셀프 어텐션(Self-Attention) 메커니즘은 모델이 시퀀스 내 모든 토큰 간의 관련성을 가중치로 측정할 수 있게 하여, 이전 RNN 기반 모델보다 훨씬 뛰어난 장거리 이해를 가능하게 합니다.
GPT-4, Claude, Gemini 등 모든 주요 파운데이션 모델은 트랜스포머 기반입니다.
주요 도구 및 프레임워크
| 도구 | 목적 | 사용 시점 |
|---|---|---|
| scikit-learn | 고전적 ML 알고리즘 | 표 형식 데이터, 설명 가능한 모델, 기준선(baseline) |
| PyTorch | 딥러닝 연구 및 프로덕션 | 커스텀 아키텍처, 연구, 유연성 |
| TensorFlow / Keras | 딥러닝 (Google 생태계) | 프로덕션 배포, 모바일/엣지 추론 |
| Hugging Face | 사전 훈련 모델 허브 | 기존 파운데이션 모델 파인튜닝 또는 활용 |
| XGBoost / LightGBM | 그래디언트 부스팅 | 구조적/표 형식 데이터 경쟁 및 프로덕션 |
고전적 ML의 시작점으로 scikit-learn이 최적입니다. 딥러닝에서는 PyTorch가 연구 분야에서 지배적이 되었으며, Keras는 딥러닝 입문자에게 더 깔끔한 API를 제공합니다.
구축 전: 데이터 전략
AI 프로젝트에서 가장 흔한 실수는 데이터 문제를 해결하기 전에 모델 선택으로 넘어가는 것입니다. 어떤 알고리즘도 나쁜 데이터를 보완할 수 없습니다.
올바른 AI 데이터 전략은 다음을 다루어야 합니다:
- 데이터 소스: 데이터는 어디서 오는가? 관심 있는 실세계 분포를 대표하는가?
- 레이블링: 지도 학습의 경우, 레이블은 어떻게 획득하는가? 인간 어노테이션? 프로그래밍 방식의 레이블링? 자기 지도 방식?
- 클래스 균형: 클래스 불균형이 있는가? (예: 정상 트래픽 99%, 악성 1%) 불균형 데이터는 특별한 처리가 필요합니다.
- 데이터 신선도: 분포가 시간에 따라 변화하는가? (예: 새로운 악성코드 패밀리) 드리프트를 어떻게 감지하고 처리할 것인가?
- 개인정보 및 컴플라이언스: 데이터에 PII가 포함되어 있는가? 어떤 보존 및 접근 제어가 적용되는가?
특히 보안 분야에서는 클래스 불균형과 개념 드리프트(공격자는 기술을 진화시킨다)가 프로덕션의 모든 모델에 영향을 주는 지속적인 과제입니다.


