





Elastic Search 개념
특징
- 루씬 기반의 검색엔진이기에 루씬을 이해하는 것이 성능 최적화에 도움이 됩니다.
- JVM 위에서 동작하며 JSON 형태로 데이터를 저장합니다.
- 데이터를 색인하고 검색을 수행하는 단위 프로세스인 노드를 기반으로 클러스터를 형성하여 동작합니다.
- 데이터는 각 노드에 분산저장이 되며 복사본을 유지하여 각종 출돌로 부터 데이터를 보호합니다.
- 기존노드에 새 노드를 실행하여 연결하는것만으로 확장가능한 분산 시스템입니다.
- 멀티테넌시를 지원 합니다.
- 실시간 및 full-text 검색이 가능하고 JSON 구조로 모든 레벨의 필드에 빠르게 접근 가능합니다.
- 사전 매핑없이 데이터를 입력하면 색인 작업이 가능하지만(스미카리스) 권장하지 않습니다.
- REST 자원을 이용 색인된 데이터의 질의 및 검색이 수행되고 이는 JSON 형식으로 문서 출력됨
- 설치가 매우 간단하고 셋팅은 conf파일 수정만으로 가능합니다.
- Curl, C#, JAVA등 여러가지 언어로 프로그래밍 하는 것을 지원합니다.
용어 설명
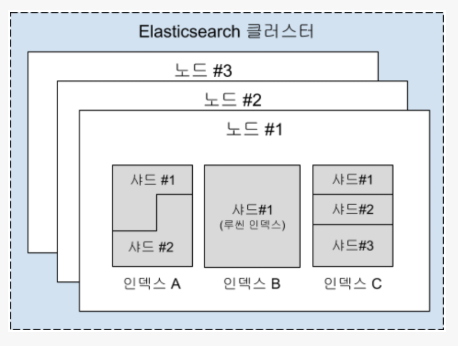
- 클러스터: 하나이상의 노드(물리적 서버)가 모인것.
- 클러스터는 고유의 이름으로 식별되며 동일한 클러스터 이름을 서로 다른 환경에서 재사용 하면 안됨
- Elastic은 기본적으로 클러스터로 동작한다.
- 노드 : 단일서버로서 데이터를 저장하고 클러스터의 색인화 및 검색 기능에 참여(Elasticsearch 실행 프로세스)
1
http://[host]:9200/
- 샤드 : 노드 안에 있는 검색 쓰레드, 샤드는 primary 또는 replica가 될 수 있다.
- primary: index를 생성할때 결정이 되며 바꿀 수 없다.
- replica: 검색 성능과 fail over 제공.
-
RDBMS와 비교
Elastic Search Relational DB Index Database Type Table Document Row Field Column Mapping Schema Shard Partition - 인덱스 : 문서(Document)의 모임, 인덱스명은 반드시 소문자로 생성해야된다.
1
http://[host]:9200/firepd
- 타입 : 논리적으로 인덱스를 분리/구분 하는 역활 -> 6.0 버전 부터 타입이 1개로 통
1
http://[host]:9200/firepd/Ticket
- 도큐먼트 : JSON 형식의 데이터
1
http://[host]:9200/firepd/esndpolicy/1?pretty&pretty
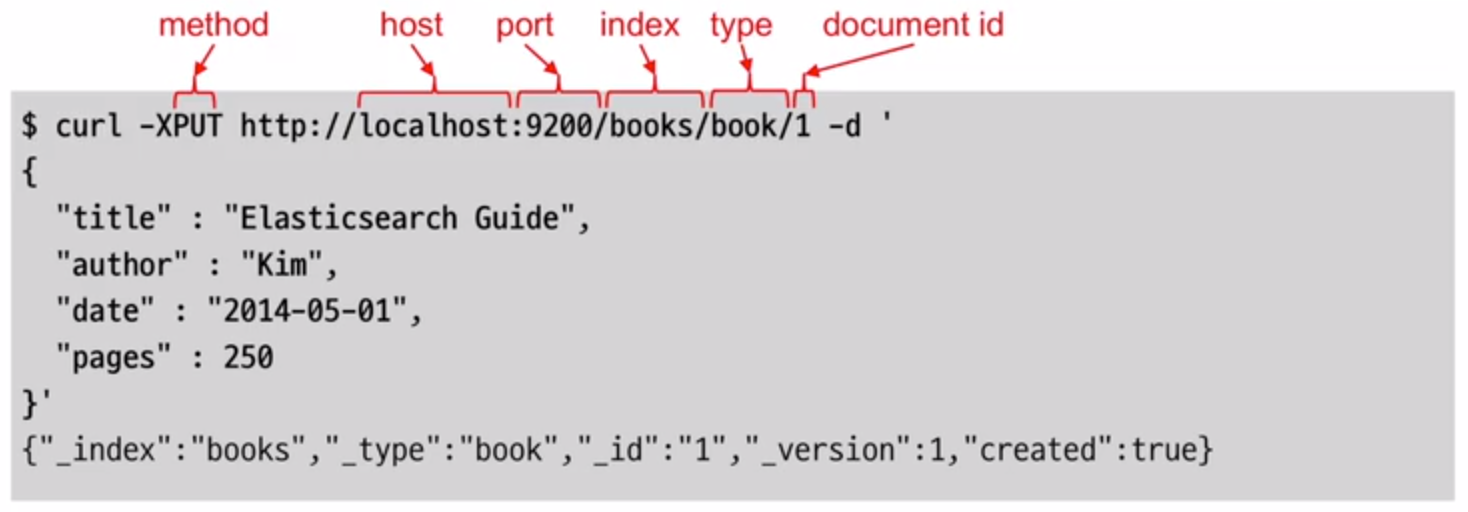
- 맵핑 : 각 타입별로 데이터 형식을 매칭
- 맵핑은 필드와 인덱스에 대해 연결 지어 주는 것이고 필드 타입에는 아래와 같은 것이 있다.

- 맵핑은 필드와 인덱스에 대해 연결 지어 주는 것이고 필드 타입에는 아래와 같은 것이 있다.
- 기본적으로 맵핑은 자동적으로 진행되지만 개발자가 직접 맵핑을 시켜 성능을 향상 시킬 수 있고 직접 매핑을 시키는 것을 권장.
- TF(term frequency)/IDF(inverse document frequency) Relevance 알고리즘을 사용 얼마나 자주 field안에 나타났는지, 얼마나 자주 index안에 나타났는지, 얼마동안이나 field안에서 검색되었는지에 따라 score가 부여된다.
- text 검색을 할 때 full-text, keyword 방식이 있고 두개는 mutual-exclusive하지만 multi-field로 이용 가능하다.

- full-text는 단어로 부분 매칭 검색이 가능하지만 keyword는 완전히 일치해야지만 검색이 된다. 따라서 “New York”와 같은 것을 검색하려면 keyword로 지정해야지 full-text로 지정하면 “New”, “York” 로 분리된 상태로 검색이 되어진다.
검색 과정
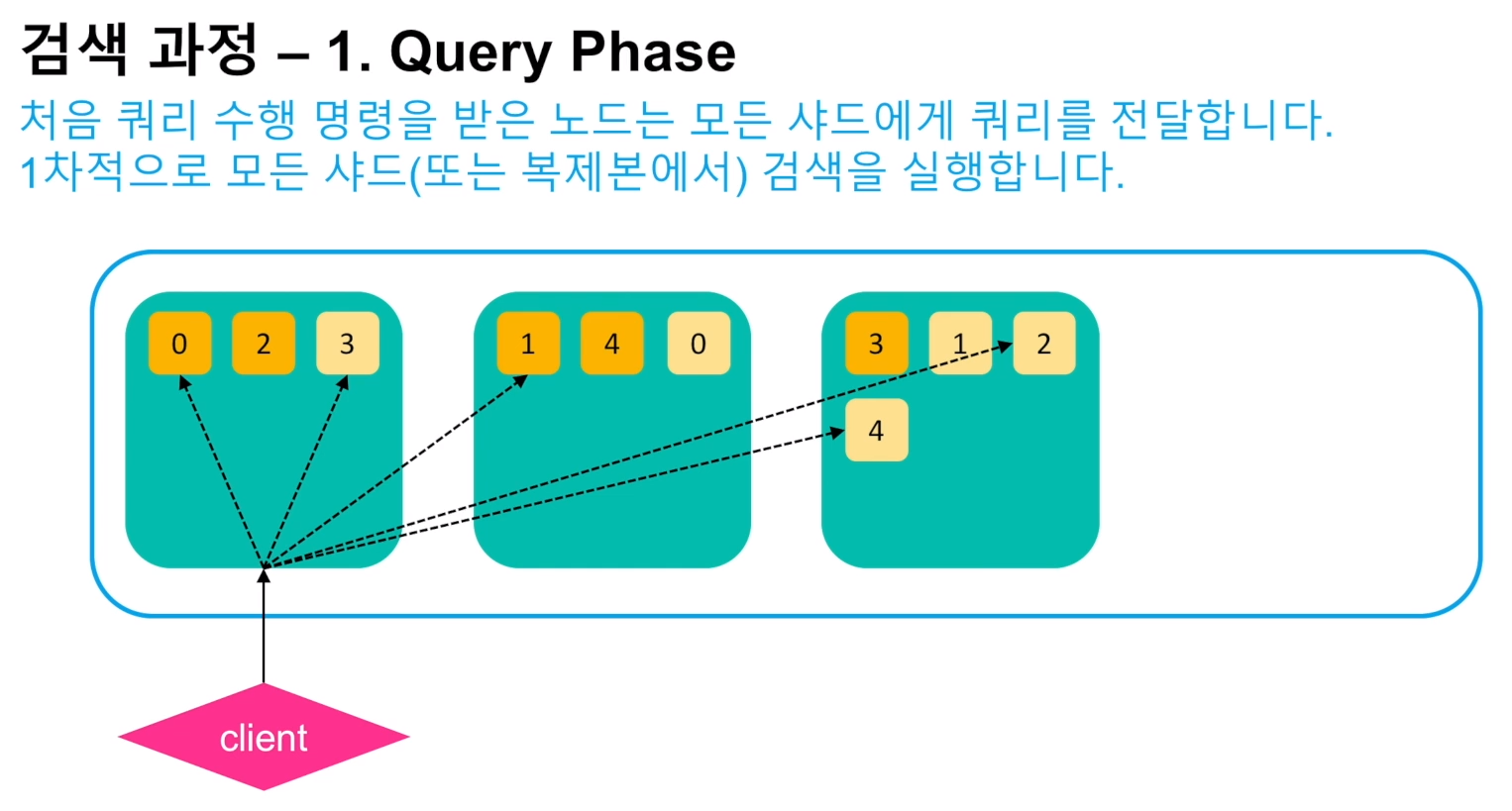
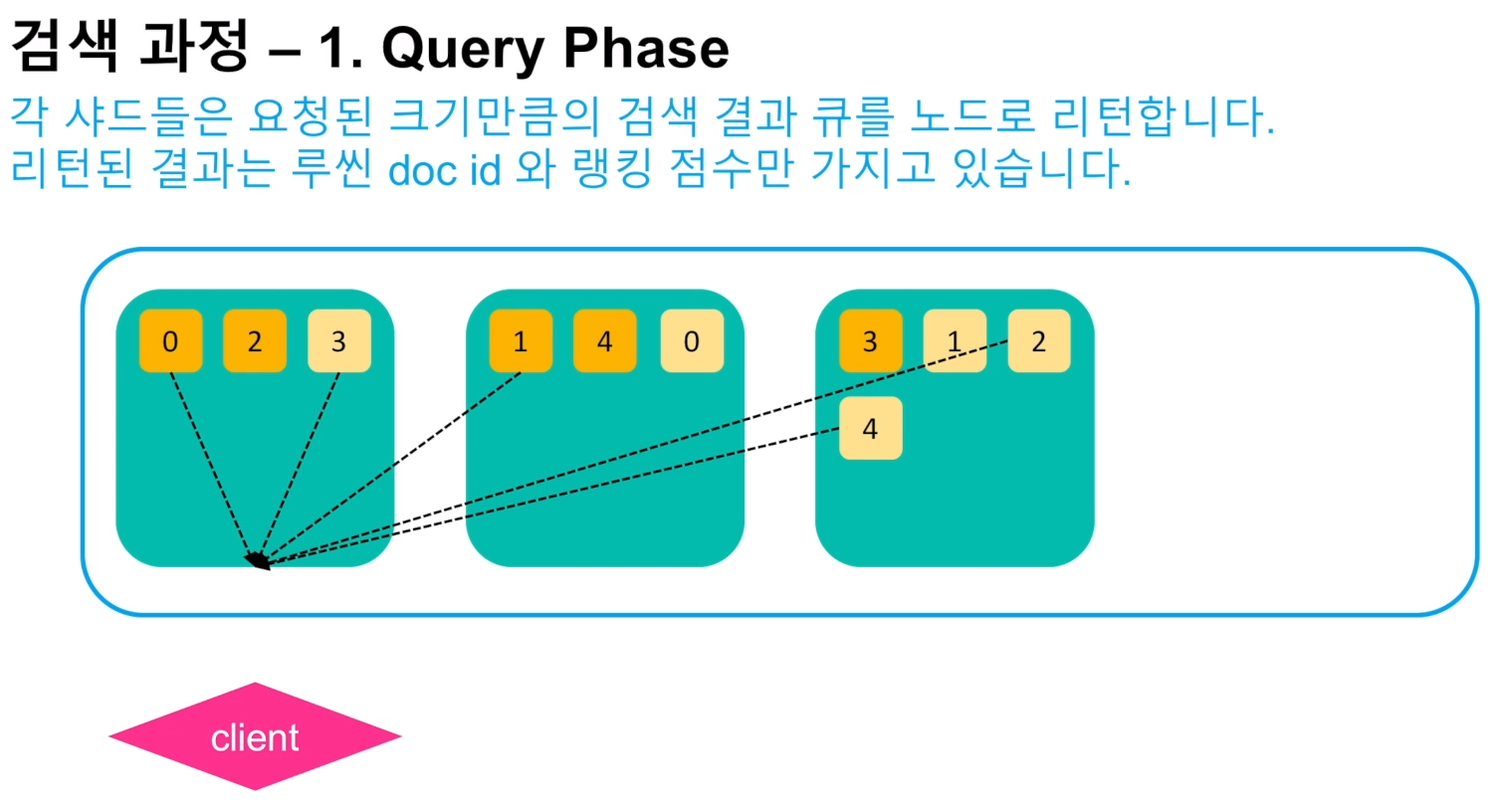
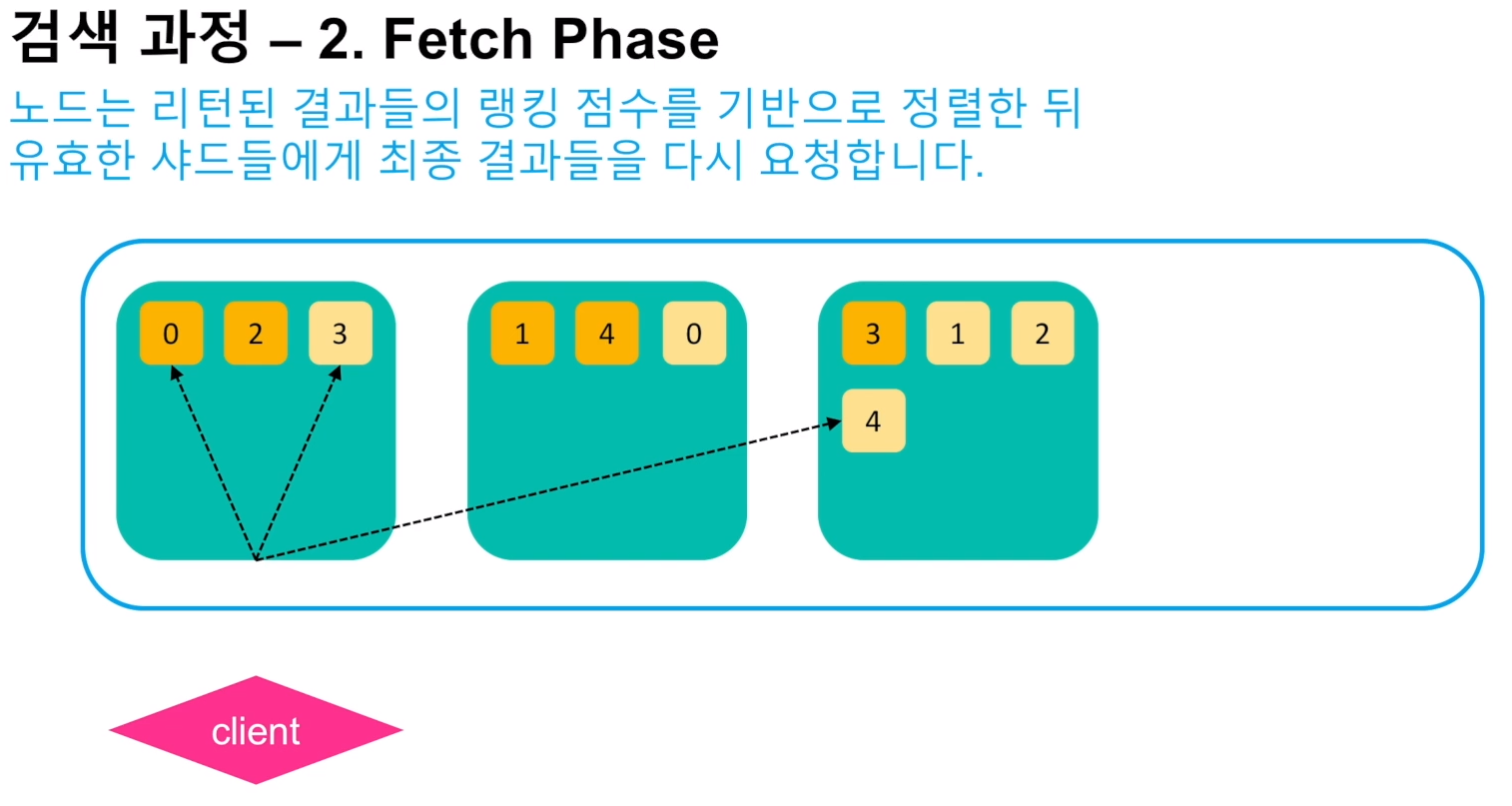
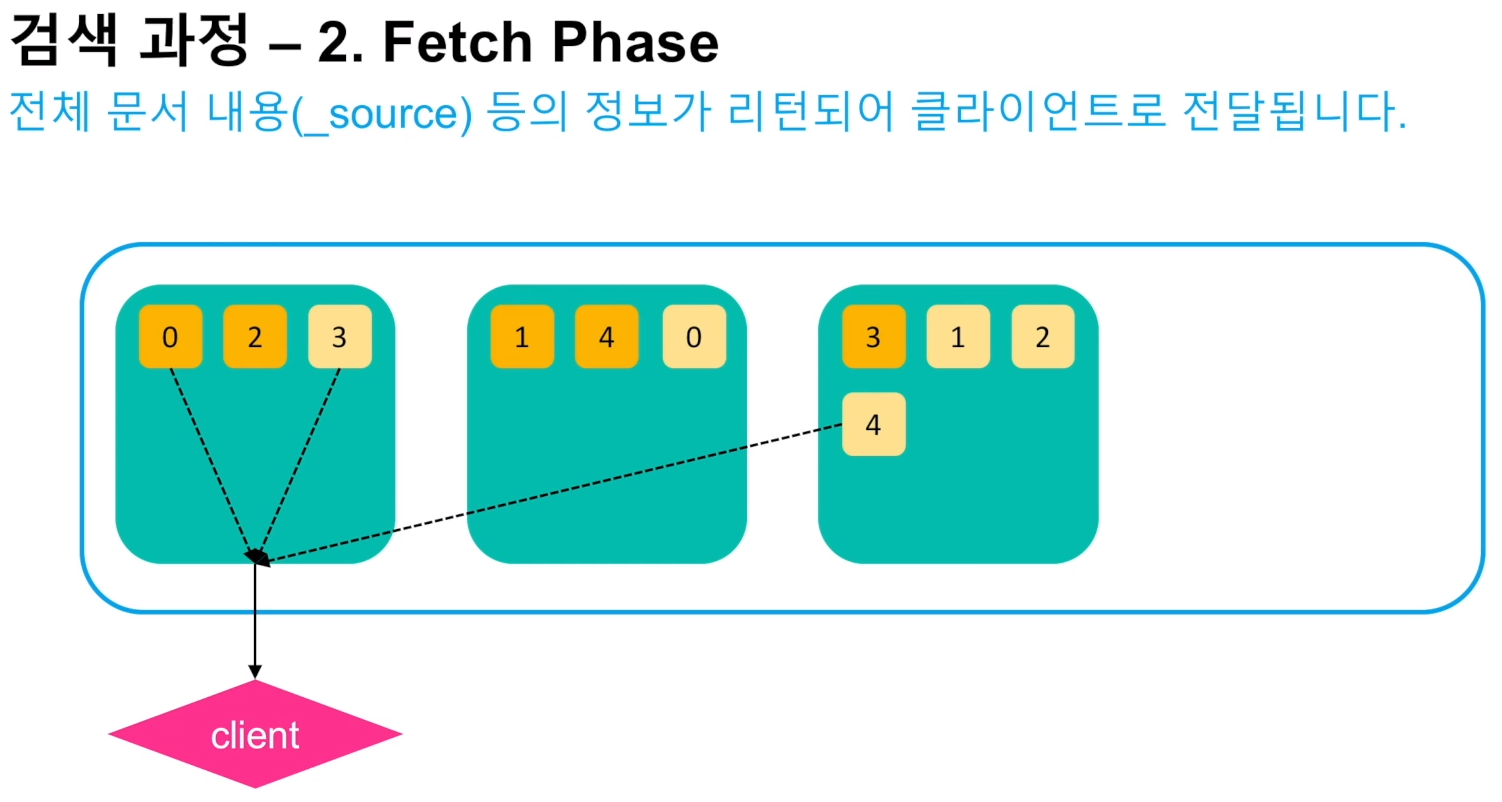
- 검색에 사용할 샤드와 노드의 수는 경험적인 방식으로 결정해야 된다. 자세한 내용은 클러스터 포스팅 참고.
추천 사이트
아래의 강의는 실습과 이론이 잘 정리되어 있어 2번정도 보는 것을 추천합니다.


