클러스터 적용
클러스터 적용을 위해 다음 절차를 확인 하셔야 합니다.
- 방화벽 9300 포트 열어놓았는지 확인하기.
- 새로운 클러스트 형성할때는 /var/lib/elasticsearch/nodes를 지우고 시작하기.
이전 데이터가 있을 경우 클러스터 형성 에러가 나는 경우가 많습니다.
/var/lib/…에 대한 경로는 설정한 것에 따라 달라질 수 있습니다. - 추가적으로 다음 공식 문서의 내용도 확인해봅니다. 공식문서
이후 elasticsearch.yml파일에 다음과 같은 코드들을 수정합니다.
cluster.name: logcenter # 클러스터 이름이 동일해야 다른 노드들이 붙을 수 있습니다.
node.name: node-master # 클러스터 과정에서 인지할 수 있는 이름으로 입력합니다.
network.host: _site_ # 특정 IP만 elastic search에 접근 할 수 있도록 허용하는 옵션.
transport.tcp.port: 9300 # elastic search client가 접근할 수 있는 TCP 포트 번호.
discovery.seed_hosts: ["192.168.0.151", "192.168.0.152"] # 클러스터에 참여하는 호스트를 적어주시면 됩니다.
cluster.initial_master_nodes: ["192.168.0.151"] # 시작시 어떤 노드들을 마스터로 할지 정합니다.
# discovery.zen.ping.unicast.hosts: ["192.168.0.151", "192.168.0.152"] # 노드가 여러개인 경우 unicast로 활성화된 다른 서버를 찾습니다. 클러스터로 묶인 노드의 IP를 지정하면 된다.
# discovery.zen.minimum_master_nodes: 2 # 마스터 노드의 선출 기준이 되는 노드의 수를 지정합니다.
index.number_of_shards: 5 # 프라이머리 샤드 갯수. 운영 중 변경 불가.
index.number_of_replicas: 1 # 레플리카 갯수. 운영 중 변경 가능.
node.master: true
node.data: false
node.ingest: false
search.remote.connect: false # Cross Cluster Search(다수의 클러스터에서 검색할 수 있는 기능) 사용 여부.
network.host값에 관한 자세한 설명.
클러스터 상태 확인
- http://192.168.0.151:9200/_cat/master?pretty
- http://192.168.0.151:9200/_cat/nodes?v?pretty
- http://192.168.0.151:9200/_cluster/health?pretty
Node 종류
- Master Node
- 모든 노드와 샤드를 관리하는 책임을 가집니다.
- 노드의 상태를 모니터링하고 있으면서 indexing 요청에 대한 데이터 라우팅을 처리하거나 검색 요청에 대한 부하를 분산하는 역할을 합니다.
- 장애 발생 시 레플리카를 이용해 샤드를 복구하는 책임을 가지고 있습니다.
node.master: true node.data: false node.ingest: false - Data Node
- 실질적인 데이터를 저장하고 검색과 통계 같은 데이터 관련 작업을 수행 합니다.
node.master: false node.data: true node.ingest: false - Ingest Node
- 문서의 전처리 작업을 담당합니다.
- 인덱스 생성 전 문서의 형식을 다양하게 변경 할 수 있다.
node.master: false node.data: false node.ingest: true - Corrdinating Node
- 사용자의 요청만 받아서 처리합니다. 일종의 load balancer의 역할입니다.
- 클러스터 관련 요청은 마스터 노드에 전달하고 데이터 관련 요청은 데이터 노드에 전달한다.
node.master: false node.data: false node.ingest: false
클러스터 구성 가이드 라인
클러스터 구성에는 노드의 종류와, 갯수도 중요하지만 프라이머리 샤드와 레플리카의 수와 크기도 중요 합니다. 우리가 예상하는 크기의 데이터를 직접 넣어보고 충분한 테스트를 해야지 최적화된 수치를 알 수 있습다.
설정값에서 5개의 프라이머리 샤드와 1개의 레플리카가 있다고 가정했을 때 인덱스 내부에는 총 10개의 샤드가 존재하게 됩니다. 이 상황에서 인덱스 총 1억 건의 데이터가 indexing 되었을 시, 각 샤드는 2천만 건의 데이터를 가지게 될 것입니다. 이런 상황에서 샤드의 부하를 줄이기 위해 장비를 추가하여 샤드 5개를 추가하는 것이 좋다고 생각할 수 있을 것입니다. 하지만 애초에 샤드의 수를 10개로 만들었으면 장비를 추가하지 않아도 될 것입니다. 따라서 프라이머리 샤드의 갯수는 설계할때부터 각 샤드가 감당해야 할 데이터의 갯수를 예상하고 설정하는 것이 좋습니다.
일반적으로 장애가 발생했을 때 빠른 복구를 위해 1개 이상의 레플리카 세트를 사용하는 것이 좋습니다. 레플리카 세트의 수를 결정할 경우 사전에 충분한 테스트가 필요한데 너무 많이 있으면 전체적인 색인 성능의 저하로 이어질 수 있기 때문입니다. 읽기 분산이 중요한 경우에는 색인 성능을 일부 포기하고 레플리카 세트의 수를 늘리는 것이 좋고, 빠른 색인이 중요한 경우에는 읽기 분산을 일부 포기하고 레플리카 세트의 수를 최소화 하는 것이 좋습니다. 복제본의 수는 운영 중에 언제라도 변경 가능하기 때문에 최초 서비스를 오픈할 때는 복제본의 수를 최소화해서 서비스 운영을 시작하고 서비스 운영 중에 발생하는 노드의 장애나 데이터량에 따라 읽기 분산을 지속적으로 모니터링 한 후 탄력적으로 복제본 수를 조절하는 것을 권장 합니다.
마스터 노드의 입장에서 샤드가 가지고 있는 데이터 건수보다는 데이터의 물리적 크기가 더욱 중요합니다. 장애 발생시 레필리카 샤드는 순간적으로 프라이머리 샤드로 전환되어 서비스 유지되고 그 때 동일한 샤드가 레필리카 샤드로 새롭게 생성 됩니다. 이 때, 샤드 단위로 데이터가 이동을 하기 때문에 데이터 건수보다는 데이터의 물리적 크기가 더욱 중요하게 되는 것입니다. 엘라스틱서치에서는 샤드 1개가 50GB를 넘지 않도록 권장을 하고 있습니다. 위의 원리를 생각하여 네트워크 비용과 마스터 노드의 부하 및 리소스 사용 관계를 잘 판단하여 샤드 크기를 결정해야 합니다. 예를 들어, 인덱스 하나가 400GB일 경우 인덱스가 2개의 샤드로 구성된다면 샤드의 크기는 200G가 될 것이고 이 경우 복구를 위한 네트워크 비용이 너무 크게 되어 적절치 않습니다. 인덱스가 400개의 샤드로 구성된다면 샤드의 크기는 1G라서 네트워크 비용은 수월할 것이지만 마스터 노드의 부하와 많은 리소스 낭비를 가져 올 것입니다.
클러스터에 존재하는 모든 샤드는 마스터 노드에 의해 관리됨으로 샤드의 갯수와 마스터 노드의 부하는 비례합니다. 검색 성능만 놓고 볼때는 프라이머리 샤드의 개수가 많을수록 검색 성능이 좋아지지만 마스터 노드의 메모리가 부족할 만큼 샤드의 갯수를 늘리면 마스터 노드에 장애가 발생하여 클러스터 전체가 마비되는 대형사고가 생길 수 있으므로 주의해야 합니다.
성능 관점에서 샤드 갯수에 대한 말씀을 다시 드리자면 샤드의 수가 너무 적으면 단일 쿼리의 응답 속도는 느려질 수 있으나 대량의 쿼리가 인입될 경우 고른 성능을 보여줄 수 있고, 샤드의 수가 너무 많으면 단일 쿼리의 응답 속도는 빠를 수 있으나 대량의 쿼리가 인입될 경우 쿼리별 성능차이가 심해질 수 있습니다. 그렇기 때문에 구축하고자 하는 클러스터의 목적에 맞게 적정한 수준의 샤드 수가 결정되어야 합니다.
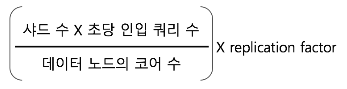
클러스터가 저장해야 할 전체 데이터 크기를 고려하여 일 별 몇 GB의 로그가 저장되며 유지 기간은 어느정도인지 예측해야 합니다. 또한 최대 동시 인입 쿼리 수를 예상해야 하고 최소한 몇 ms안에 응답을 줄 수 있게 할 지에 대한 계산을 해야 합니다. 위의 예상결과와 더불어 실제 사용할 수 있는 하드웨어 스펙을 결정하여 샤드의 수를 결정해야 할 것입니다.
예를들어 클러스터 데이터 크기가 3TB(일 별 최대 100GB, 최대 30일 보관), 초당 최대 인입 쿼리 수 10개, 목표 검색 쿼리 응답시간 100ms,
24 Core / 32GB MEM일때 샤드의 크기는 대략 26GB가 되어야 합니다. 이 때 샤드는 5개 정도로 설정하면 되고 초당 인입되는 쿼리 수를 계산하여
노드의 갯수를 설정합니다. 대략 6대의 노드가 필요합니다.
자세한 테스트 방식과 설명에 대해서는 다음 블로그가 잘 설명하고 있습니다. 참고
클러스터 성능 측정 도구인 랠리를 사용 할 수 있습니다.
하나의 샤드에서 indexing할 수 있는 문서의 수는 대략 2,000,000,000개이고 인덱스는 최대 1024개까지 가질 수 있습니다. 따라서 인덱스가 가질 수 있는 최대 문서 수는 대략 2,000,000,000,000 입니다.
엘라스틱서치는 메모리를 많이 사용하는 애플리케이션인데 JVM 힙에 메모리를 할당해서 사용합니다. 힙 크기는 32G 이하로 유지해야 합니다. 더불어 OS에 최소 50% 메모리 공간은 보장해야합니다. 일반적으로 엘라스틱에 부여되는 힙 크기가 클수록 성능이 좋아집니다. 메모리의 스펙이 매우 클 경우 32G 메모리 엘라스틱 서치 인스턴스를 여러개 만드는것이 좋습니다.
인덱스 최적화(Index Optimization)를 수행하면 세그먼트를 병합시킬 수 있습니다. 이러한 방식으로 검색 성능을 향상시킬 수 있지만 시스템에 부담을 줌으로 시스템 사용이 적은 시간대에 작업하도록 해야 합니다.
$ curl -XPOST 'http://localhost:9200/log-2012-10-01/_optimize'